

📌TIPS:先讓你的ChatGPT(Gemini, NotebookLM, …)幫你讀這篇論文,請ChatGPT做點分析工作,然後,將你投資組合裡面的 AI Agent 公司丟給 ChatGPT 幫你分析,這家公司的產品哪些是綠區、哪些誤踩了紅區,甚至是低效無用區。
6月5日,一篇由史丹佛大學團隊發表在 arXiv 的論文,題為「未來工作與 AI 代理:審視勞動力的自動化潛力」(Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the U.S. Workforce)。
這篇論文首先建立了名為 WORKBank 的資料庫,它從第一線工作者和 AI 專家的雙重視角出發,審視了哪些任務適合由 AI 代理自動化,而哪些則更適合由人類主導。其中一個結論讓我印象深刻:在矽谷頂尖創業加速器 Y Combinator 的投資組合中,有相當高的比例竟然落在「低優先級區」和「紅燈區」。
Y Combinator 是矽谷首屈一指的創投公司,OpenAI、Dropbox、Stripe 等知名公司都發跡於此。它的投資方向往往代表著早期投資界的趨勢。然而,這篇論文發現,在 84 家 YC 支持的 AI Agent 新創公司中,高達 41% 的專案落於前述的兩個區域:低優先級區與紅燈區。
何謂「低優先級區」呢?它指的是工作者對任務自動化的需求不高,同時 AI 技術實現起來也缺乏顯著優勢的任務。換言之,使用者本身不希望 AI 來執行這項任務,且即使 AI 介入也無法帶來顯著效益。
而「紅燈區」則更為複雜。雖然 AI 技術確實有能力執行這些任務,但工作者卻強烈不希望其被自動化。舉例來說,醫療診斷、心理諮詢、教育輔導等類型的任務,便經常出現在紅燈區。從商業角度來看,這些領域的「信任成本」極高;即使技術上可行,也並不意味著投入資源去自動化是值得的。
這種「錯位」現象的背後,其實反映了一個普遍存在的盲點:技術開發者和投資人往往容易高估「技術可實現性」,卻低估了「市場接受度」。也就是說,我們經常過度興奮於 AI 能做什麼,卻忽略了人類是否願意讓它去做。
反觀之,論文也指出真正值得優先投入的領域是「綠燈區」和「研發機會區」。前者是技術可行且使用者樂於接受自動化的任務;後者則是使用者強烈希望自動化,但目前技術尚未達到預期的任務。這些才是真正兼具商業可行性與技術挑戰性的發展方向。
作為創投 VC,我對 AI Agent 的未來充滿期待。然而,從投資角度出發,我也越來越體會到:關於自動化這件事,絕非僅僅考量「能否做到」,更應深思熟慮「值不值得做」。
特別是在當前 AI 創業高度泡沫化的階段,判斷一個專案是否屬於「紅燈」或「綠燈」,其重要性甚至可能超越對模型參數的評估。未來真正龐大的商機,應該潛藏在人類願意「交出去」、而 AI 又恰好能「接得住」的交會點上。這也是我近期在進行投資判斷時,會特別著重去關注的面向。
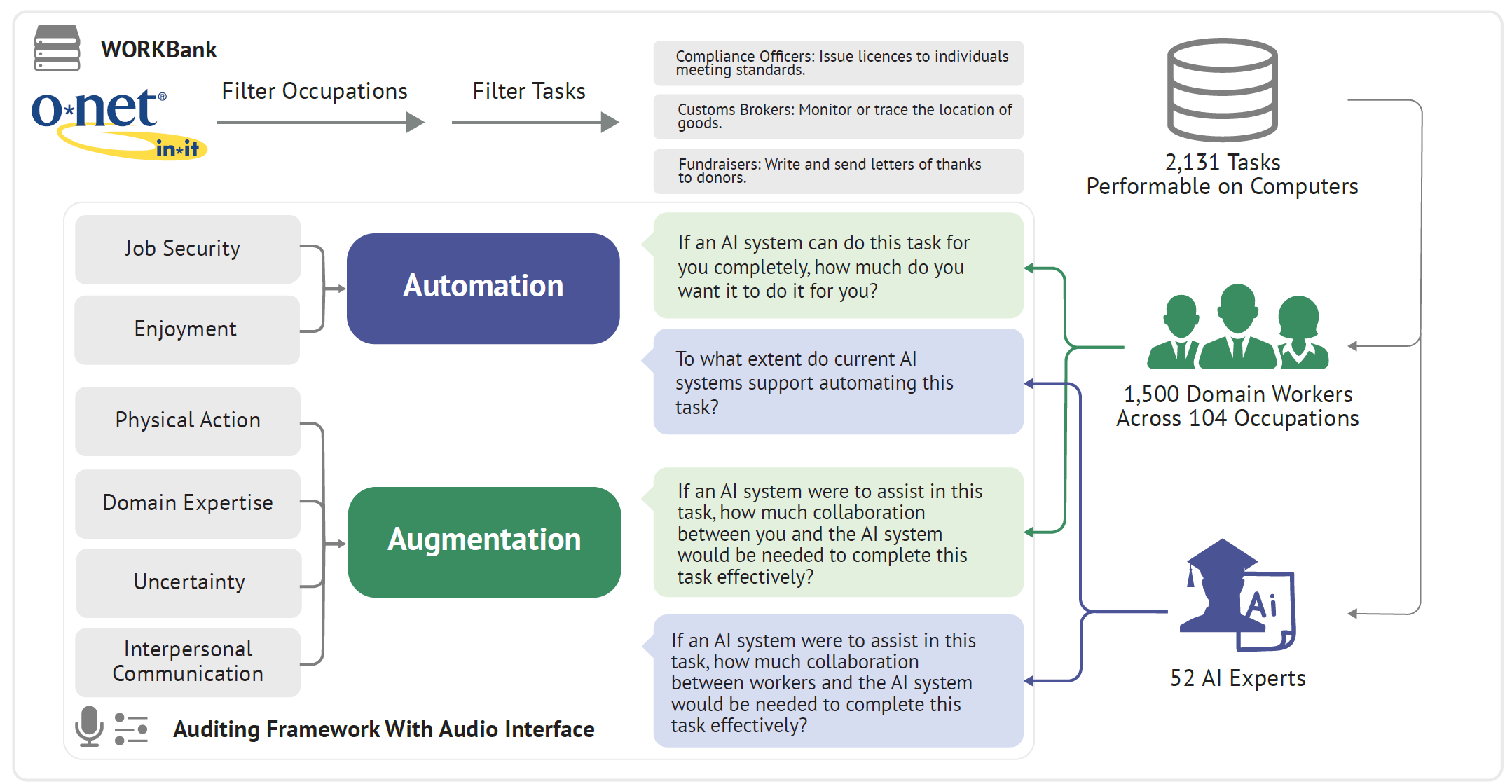
1. 研究框架(Auditing Framework)
論文的核心是一個新穎的檢視框架(Auditing Framework),它結合了人類對 AI 應用的期望和當前的 AI 技術能力。這個框架將任務劃分為四個區域,為理解 AI 的潛在影響提供了一個清晰的藍圖:
人類代理量表(Human Agency Scale, HAS):為了量化人類對 AI 參與的偏好,論文引入了 HAS。這個量表是一個共享的語言,用於描述和評估人類在任務執行中所需的控制程度和參與水平。它為後續的訪談和數據收集提供了標準化的衡量工具。
2. 資料庫建構:WORKBank
論文的核心貢獻之一是構建了一個名為 WORKBank 的大型資料庫,它基於美國勞工部的 O*NET 資料庫,並進行了擴展。WORKBank 包含了兩個主要的數據來源:
從業者偏好數據 (Worker Preferences Data):
資料來源: 論文從 O*NET 資料庫中選取了 104 個代表性的職業,並從這些職業中提取了 844 項任務。
數據收集方法:
音頻增強的迷你訪談 (Audio-Enhanced Mini-Interviews): 這是一個關鍵的創新點。研究人員招募了來自不同職業的 1,500 名領域工作者。每個工作者被要求就其職業中的特定任務,通過音頻訪談的形式表達他們對於 AI 代理是自動化(完全由 AI 完成)還是輔助(AI 幫助人類完成)的偏好。這種迷你訪談的方式旨在捕捉從業者對 AI 應用更細微、更豐富的意願和顧慮。
HAS 應用: 在訪談中,研究人員會引導工作者使用 HAS 來量化他們對人類參與水平的偏好。例如,他們可能被問到,對於某項任務,他們希望 AI 是完全自動化,還是作為一個輔助工具,或者完全不需要 AI 介入。
數據類型: 每個任務都有對應的從業者偏好分數,反映了他們對 AI 自動化或輔助的期望。
AI 專家能力評估數據 (AI Expert Capability Assessments Data):
資料來源: 針對 WORKBank 中的 104 個職業,研究人員招募了 AI 領域的專家。
數據收集方法:
專家評估: AI 專家被要求評估 AI 代理在執行這些職業的特定任務方面的技術能力。評估的維度可能包括 AI 完成任務的效率、準確性、複雜性等方面。
現有技術考量: 評估通常基於當前最先進的 AI 技術水平,以確保評估的實用性和可行性。
數據類型: 每個任務都有對應的 AI 技術能力分數,反映了 AI 目前能夠在多大程度上完成該任務。
Human Agency Scale(HAS)
當我們思考 AI agents 如何進入職場,我們不能只問「這個工作能不能被 AI 完全取代」,而更應該問:「這個任務適合讓 AI 參與到什麼程度?」這就是 Human Agency Scale(人機協作量表) 的核心目的──建立一個量化人類參與程度的共通語言,進一步劃分哪些任務應該自動化,哪些則應強化人機協作。
HAS 模型背後的關鍵理念
補足「自動化 vs. 非自動化」的二分思維
現實世界的任務多半落在灰色地帶,例如:AI 可生成初稿,但仍需人編輯潤飾(H3H4);或 AI 可快速提出分析建議,但關鍵決策仍需人把關(H4H5)。從人類角度出發,而非技術可行性本位
不同於 SAE 自駕車分級(L0–L5)由機器主體定義,HAS 以「人類在任務中想扮演什麼角色」為中心,反映工作者價值觀與自主性。為開發者與政策制定者提供指引
不同的 HAS 級別,對應不同的 AI agent 設計目標與部署風險。例如:H1-H2 適合追求效能、成本與一致性的自動化應用
H3 強調人機協同設計(如共同編輯、流程建構)
H4-H5 需設計具備回饋機制與人類決策支援的 AI
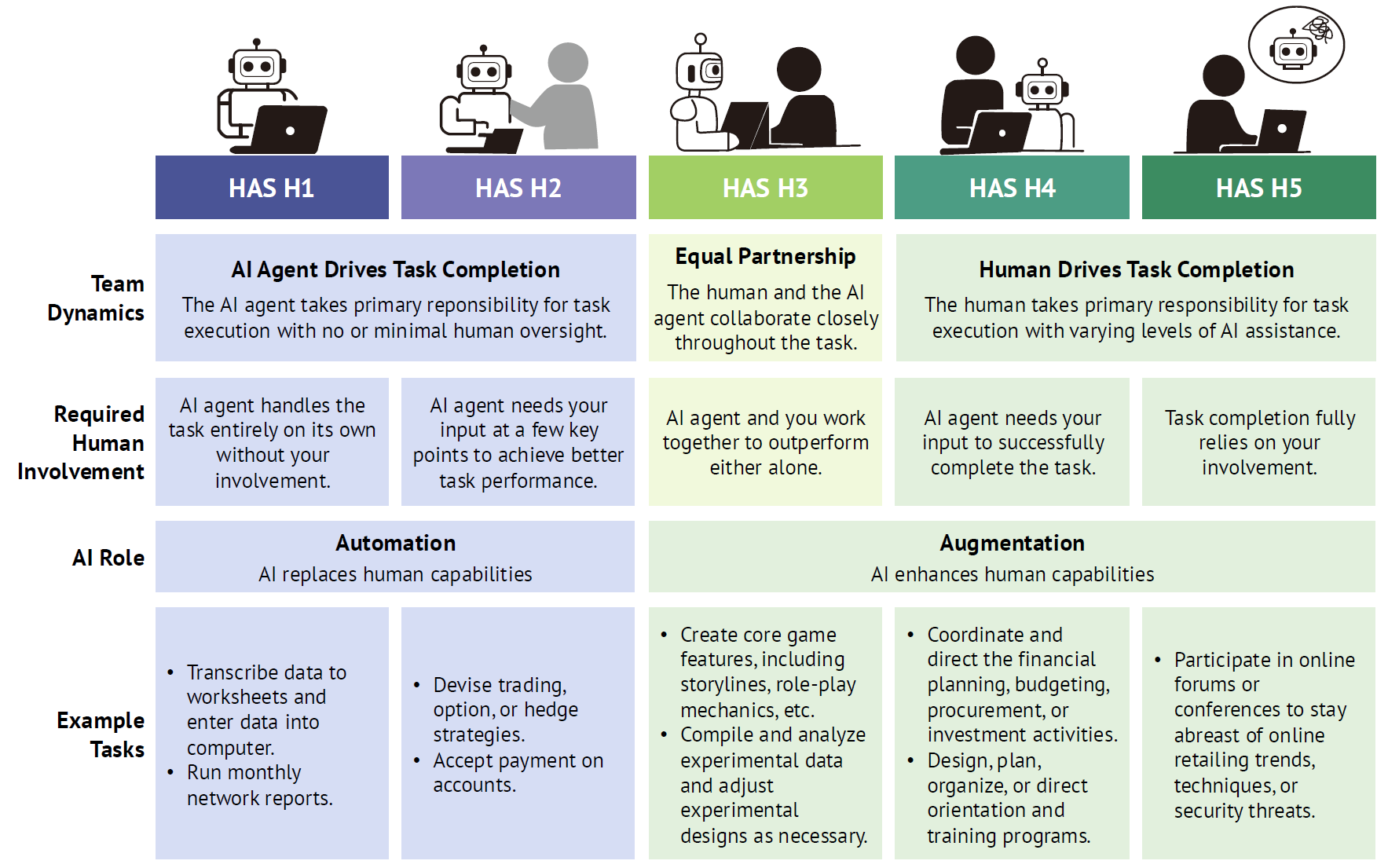
為什麼 HAS 比「能不能取代人類」更重要?
因為未來工作的問題,不是單純地問「這工作會不會被 AI 搶走?」,而是:
「我願意讓 AI 協助我多少?在哪些部分?」
HAS 為企業、從業者與技術開發者提供了一個共享的判準,幫助我們設計出真正符合人類價值、增進工作品質的 AI agent。
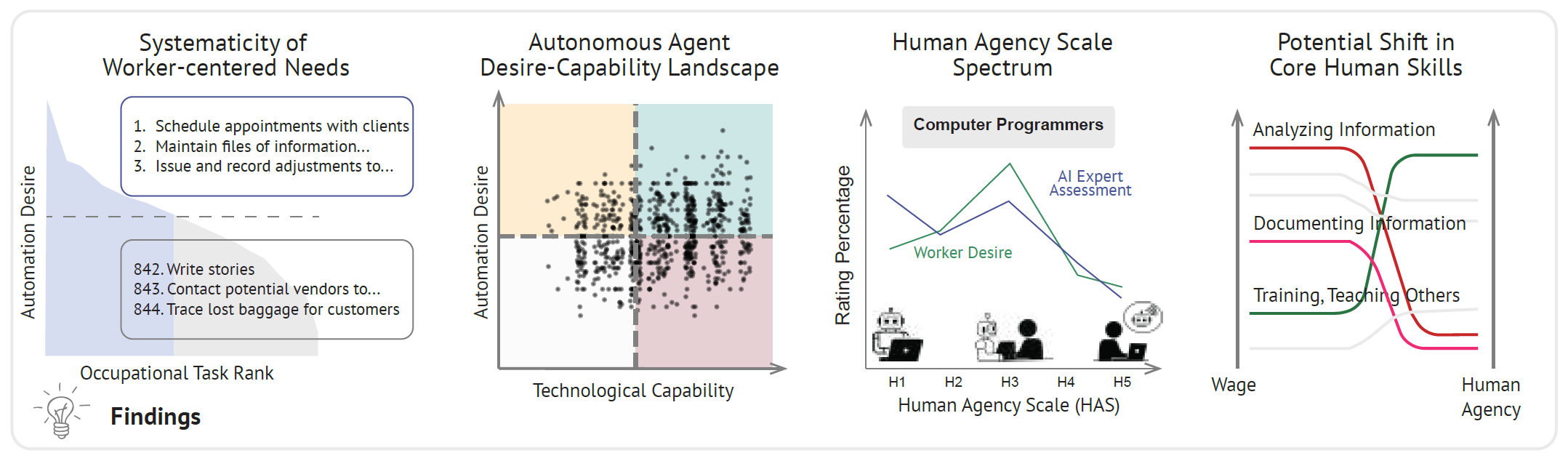
Desire–Capability Landscape 四象限
每個任務根據:工作者希望自動化意願、目前AI 技術的可行性,劃分成四個象限:
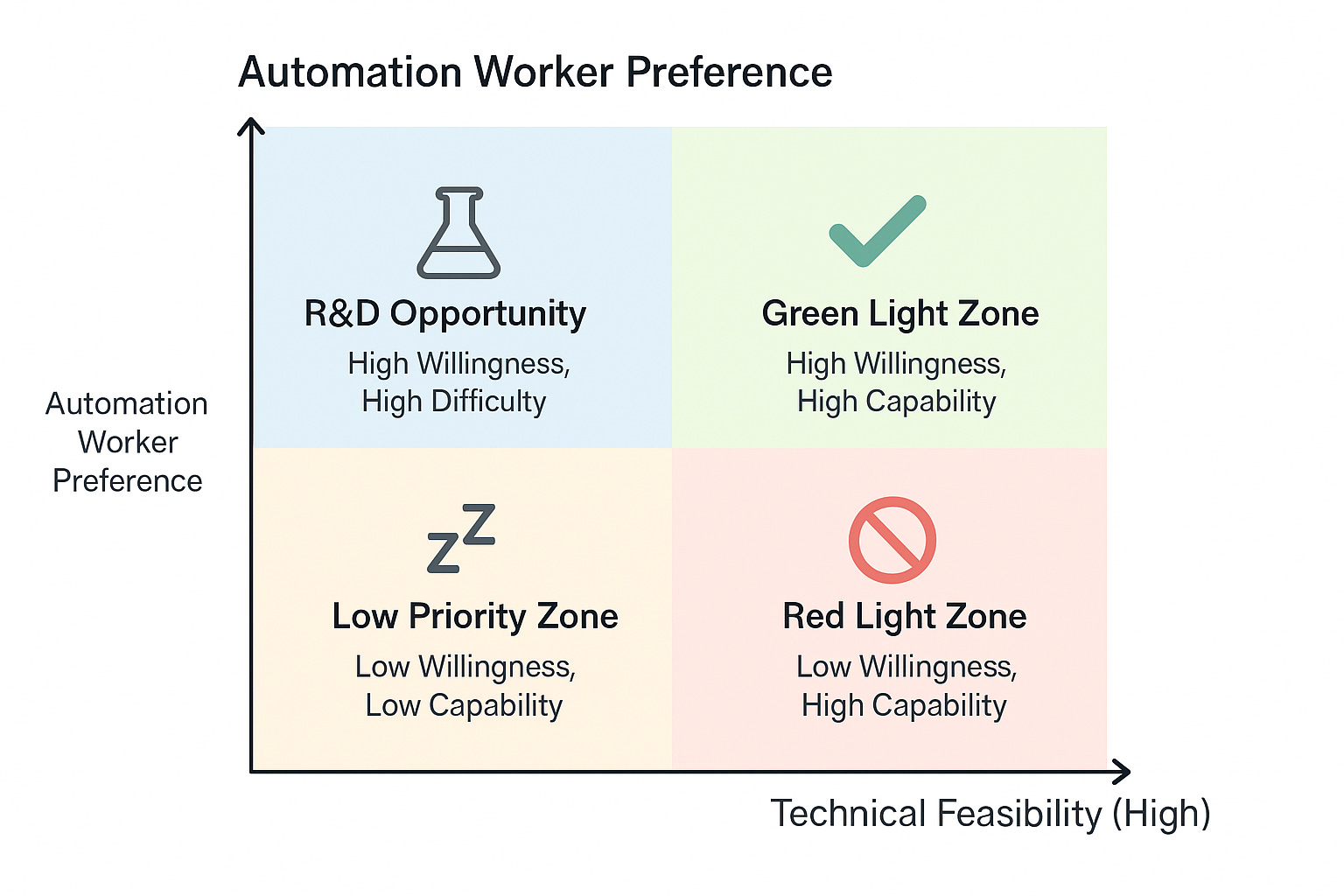
R&D Opportunity 區域(高願望 × 低技術可行性)
從業者非常希望 AI 來完成該任務,但目前 AI 技術尚無法勝任
這些任務存在潛在市場需求,但技術尚未突破
對 AI startup、學術界與技術研究團隊來說,是創新研發的優先候選任務
若能攻克,將能快速獲得從業者採納與市場認可
根據論文 WORKBank 資料庫與圖表內容,以下是屬於 R&D Opportunity 區域的典型任務類型與職業代表:
R&D Opportunity 區域約占總任務數量的 13–15%
任務集中在「中等技術門檻但人類希望高」的區域,並非極端冷門或超高難任務
常見於「規劃」「說明」「撰寫」「整理」類任務,而非純動作型
AI Agent時代:未來的職場價值變化

這張圖表是本論文中極具洞見:它揭示了在 AI agents 快速演進的背景下,薪資水平與「人類主導需求」(Human Agency)之間的潛在斷裂,並指出一個正在成形的未來職場趨勢警訊:未來的職場價值將不再只是由市場報酬決定,而是由「人是否不可取代」來主導。
紅色線:高薪但可自動化任務,未來可能貶值
這些任務目前高薪,但 AI 技術已能執行,未來存在「人類價值稀釋」風險:
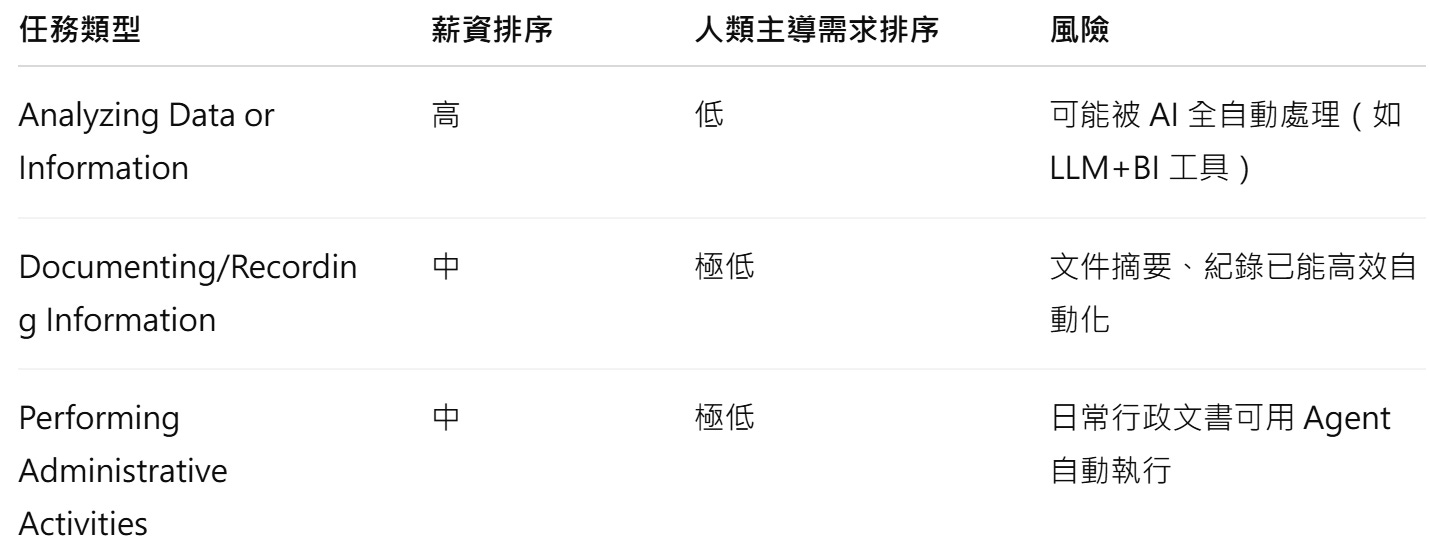
📌 這些任務過去被認為「需技能、高薪」,但未來可能快速失去勞動市場價值。
綠色線:低薪但人主導任務,未來具升值潛力
這些任務目前報酬不高,但因為具有高人際互動性、情境不確定性或倫理責任,難以被 AI 替代:

📌 這些任務會因「無法輕易自動化」而變得稀缺與有價值,潛在薪資有上升空間。