


本文為 Julie Sheridan Eng 博士(Coherent Corp. CTO)於 2026 年 3 月在美國洛杉磯舉辦之 OFC 2026(光纖通訊會議暨展覽會,Optical Fiber Communication Conference and Exposition) 年會全體大會(Plenary Session)主題演講(Keynote Speech)之摘要紀錄與技術延伸整理。
Julie Sheridan Eng 博士以近三十年深耕光通訊產業的視角,系統性回顧光子學技術從長距骨幹電信、企業資料中心、超大規模雲端,演進至當前 AI 資料中心時代的四個關鍵世代,並深入剖析頻寬密度、能源效率、建置成本的產業里程碑,以及 Scale Up、Scale Out、Scale Across 三域互連架構在 AI 算力擴展浪潮下的技術挑戰與解決路徑。
本文在忠實呈現演講核心論述的基礎上,進一步援引光通訊業界 IEEE、OIF、ITU-T 等標準組織慣用技術術語,補充必要的物理原理、系統規格與產業背景,以供研究人員、工程師及產業決策者參考。
OFC Conference 2026 - Plenary (影音片段12:30 - 48:00)
投影片
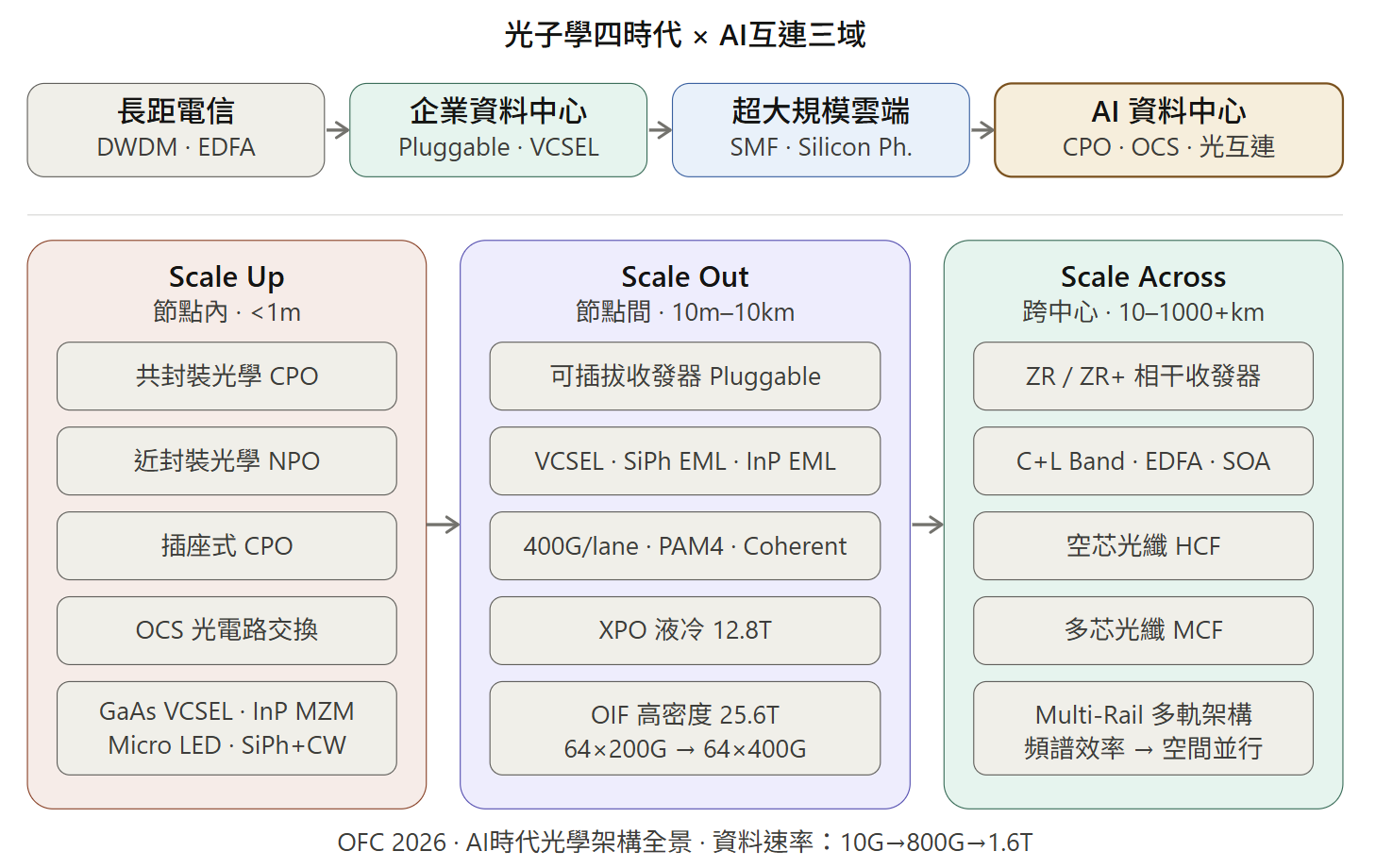
一、光子學的四個世代
回顧近三十年的OFC歷程,Julie Sheridan Eng 將光子學發展劃分為四個世代:
第一世代|長距骨幹電信(1980–1990年代)
核心技術標誌為密波分多工(DWDM, Dense Wavelength Division Multiplexing),利用ITU-T G.694.1所規範的100GHz或50GHz通道間隔,在單根光纖中並行傳輸數十乃至數百個波長。搭配摻鉺光纖放大器(EDFA, Erbium-Doped Fiber Amplifier),解決長距傳輸的光訊號衰減問題,奠定C波段(1530–1565nm)骨幹傳輸的技術基礎。
第二世代|企業資料中心
可插拔光收發器(Pluggable Transceiver)與垂直共振腔面射型雷射(VCSEL, Vertical-Cavity Surface-Emitting Laser)主導市場。VCSEL因具備低閾值電流、圓形光束輪廓、易於陣列整合等優勢,廣泛應用於多模光纖(MMF)短距連接,成為SFP、QSFP等標準外形規格(Form Factor)的主要光源技術。
第三世代|超大規模雲端資料中心(Hyperscale)
Google、Meta、Microsoft等雲端業者的大規模部署推動單模光纖(SMF, Single Mode Fiber)全面普及,同時催生矽光子(Silicon Photonics, SiPh)的商業化應用。矽光子利用成熟的 CMOS 後段製程(BEOL),在矽晶片上整合調製器(Modulator)、波導(Waveguide)、光電偵測器(Photodetector)等元件,實現高整合度與規模化量產的雙重優勢。
第四世代|AI資料中心(當前進行式)
光學已從網路基礎設施的幕後角色,躍升為AI系統架構設計的核心決策要素。光互連的頻寬(Bandwidth)、延遲(Latency)與功耗(Power Consumption)直接決定AI訓練叢集的效能上限,光子技術的創新節奏已成為AI算力擴展的關鍵制約因素。

二、產業里程碑:頻寬密度、能效與成本

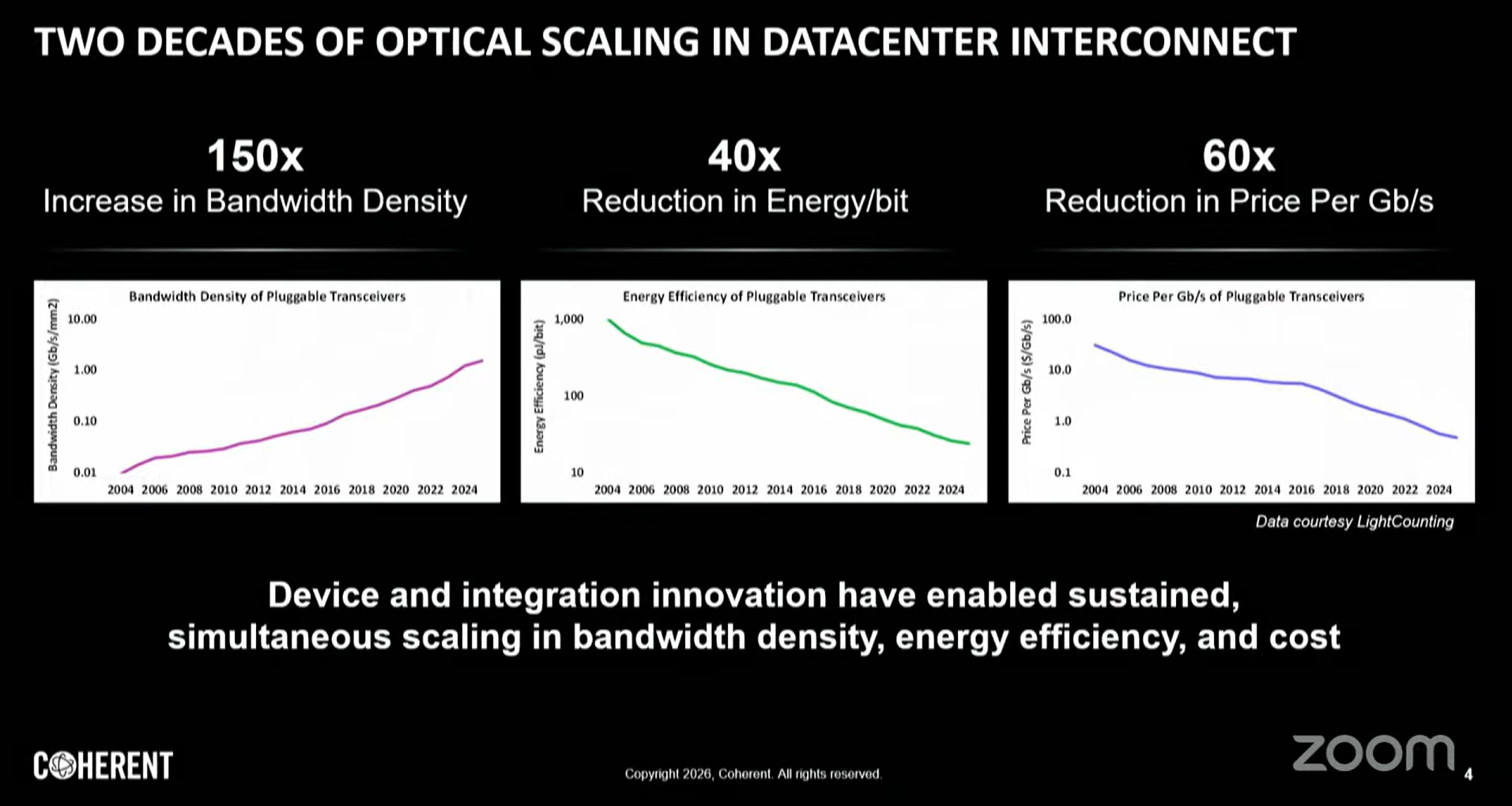
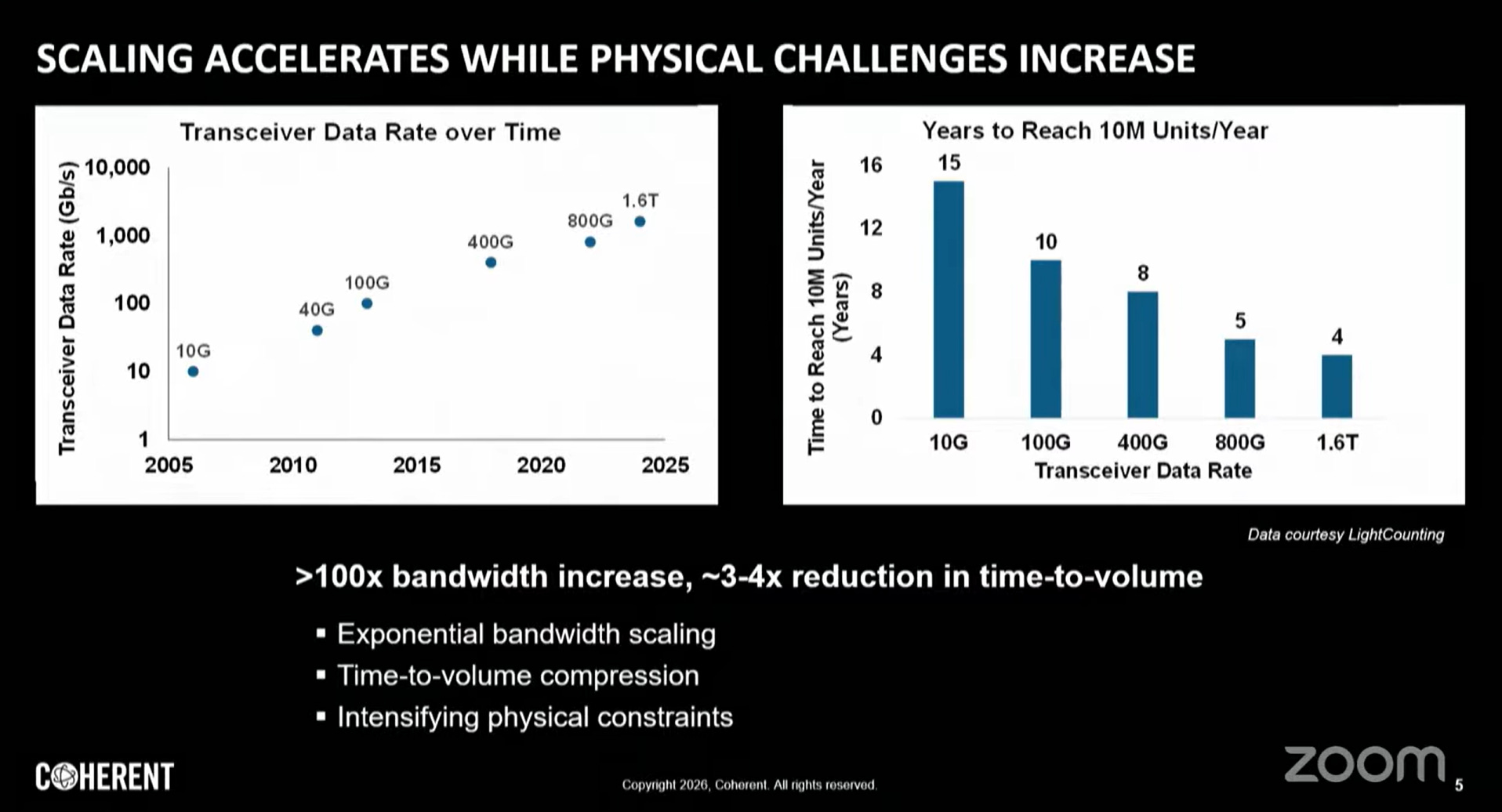
光收發器資料速率演進呈現指數增長,而更關鍵的是達到規模量產所需時間的急遽壓縮:
10G:從技術推出至年出貨量突破1,000萬埠,歷時約 15年
800G:同等量產規模僅需約 5年
1.6T:預估僅需約 4年
此趨勢反映AI基礎設施需求對光學產業研發、製程成熟與供應鏈建立週期的強力壓縮。
技術補充|能效指標:衡量收發器能效的核心指標為每傳輸位元功耗(pJ/bit)。當前主流800G DR8收發器功耗約14–16W,折算約18 pJ/bit;下一代1.6T目標需降至10 pJ/bit以下,對電吸收調變器(EAM)或馬赫-曾德爾調變器(MZM)的驅動電壓與串擾消光比(ER, Extinction Ratio)提出更嚴苛的設計要求。
三、AI算力缺口與互連依賴度攀升
訓練大型語言模型(LLM)所需算力每年成長約 4.5倍,遠超摩爾定律(Moore’s Law)每兩年提供的製程增益(約年均1.41倍)。此一「算力-製程」缺口驅動系統擴展策略全面轉向平行化(Parallelism):
資料並行(Data Parallelism, DP):模型複製至多個加速器,各處理不同微批次(Micro-batch)
張量並行(Tensor Parallelism, TP):矩陣運算按行/列切分至多個加速器,需要高頻寬集合通訊(Collective Communication),如All-Reduce、All-Gather
流水線並行(Pipeline Parallelism, PP):模型各Transformer層分配至不同節點,以流水線方式執行前向與反向傳播
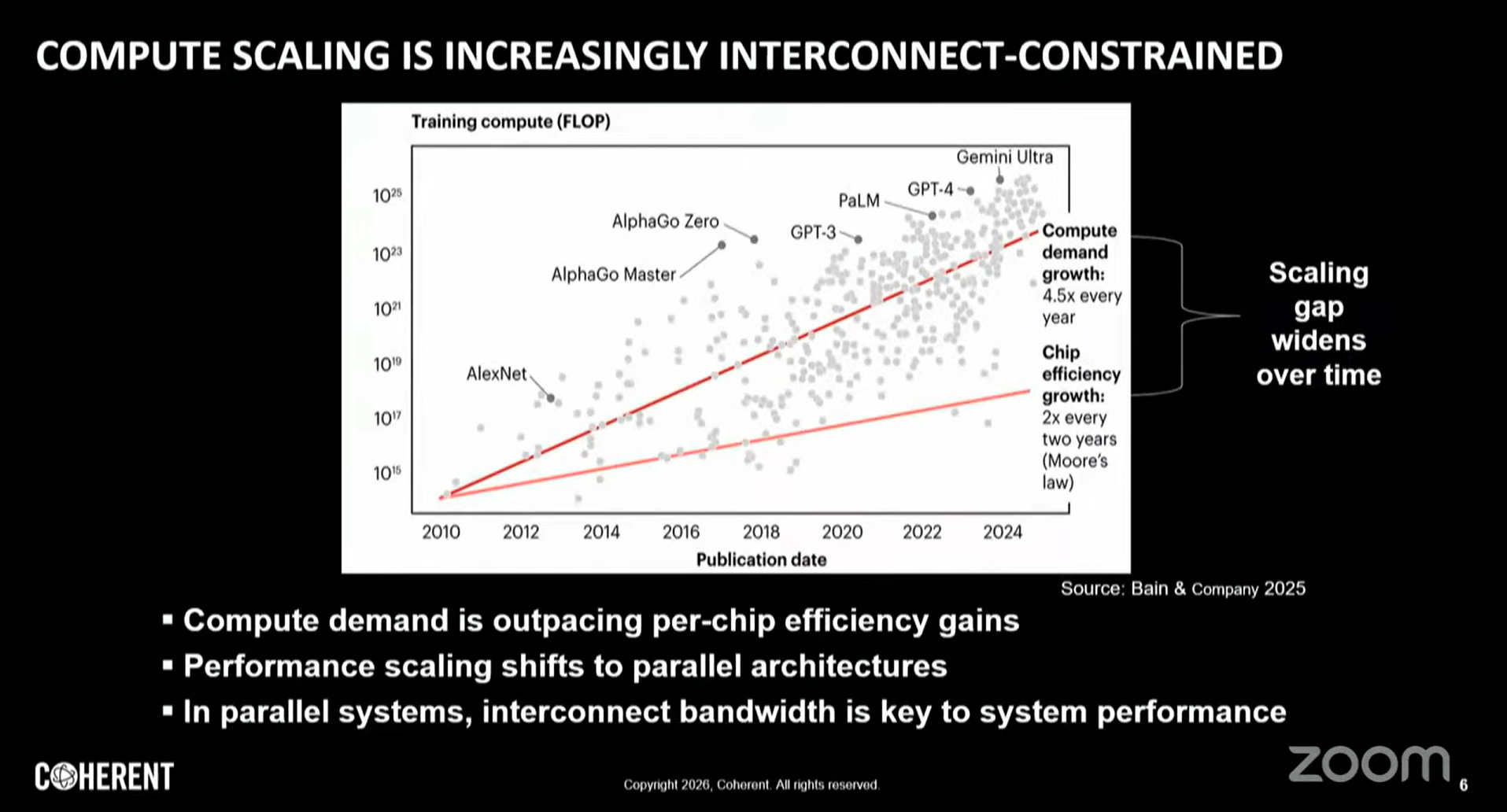
平行度越高,節點間的互連頻寬(Interconnect Bandwidth)與通訊效率(Communication Efficiency)對整體系統吞吐量(System Throughput)的貢獻權重越大。光互連在此架構下從附屬元件躍升為系統效能的決定性瓶頸。
AI資料中心互連三域架構:
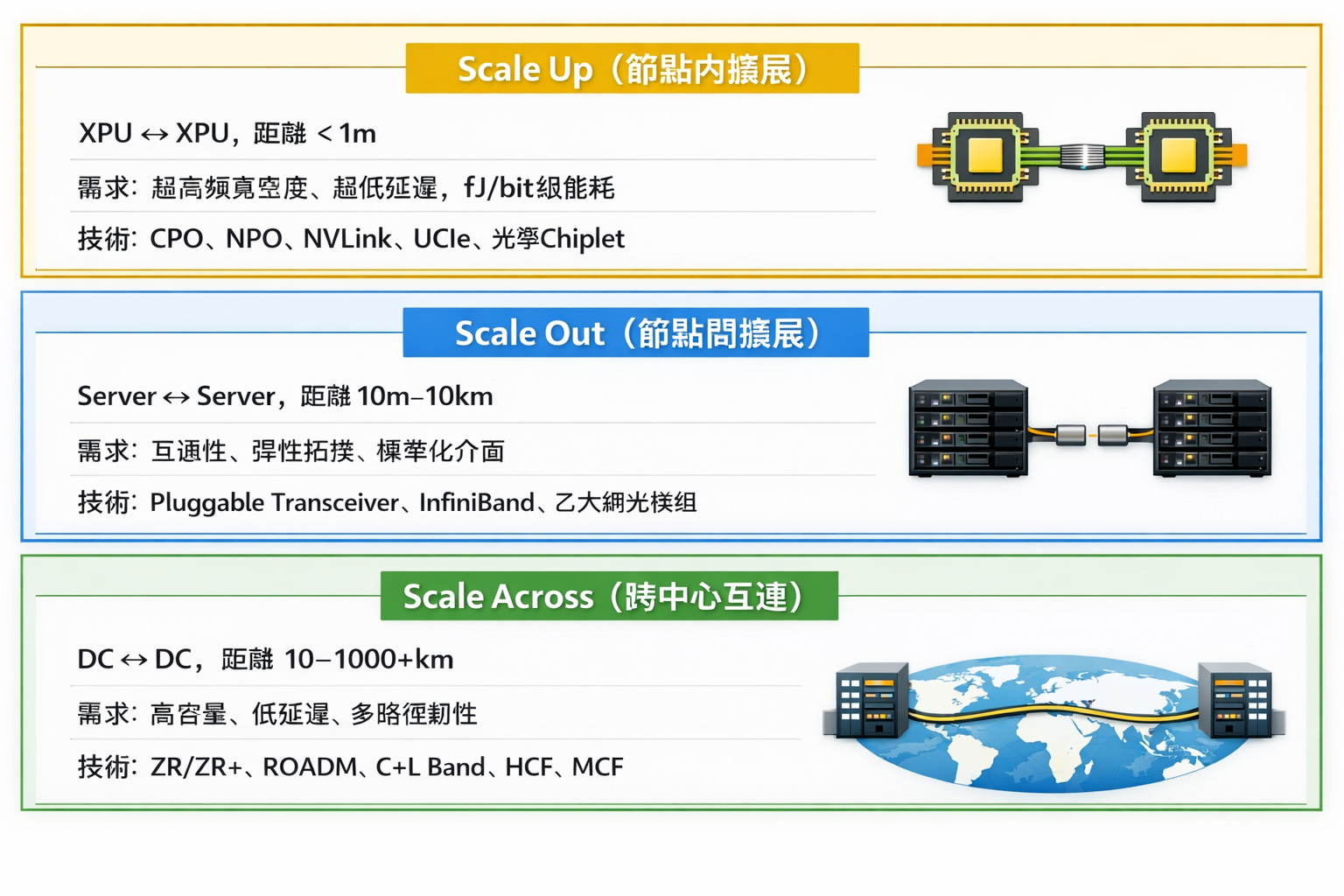
架構定義:Scale Up vs. Scale Out
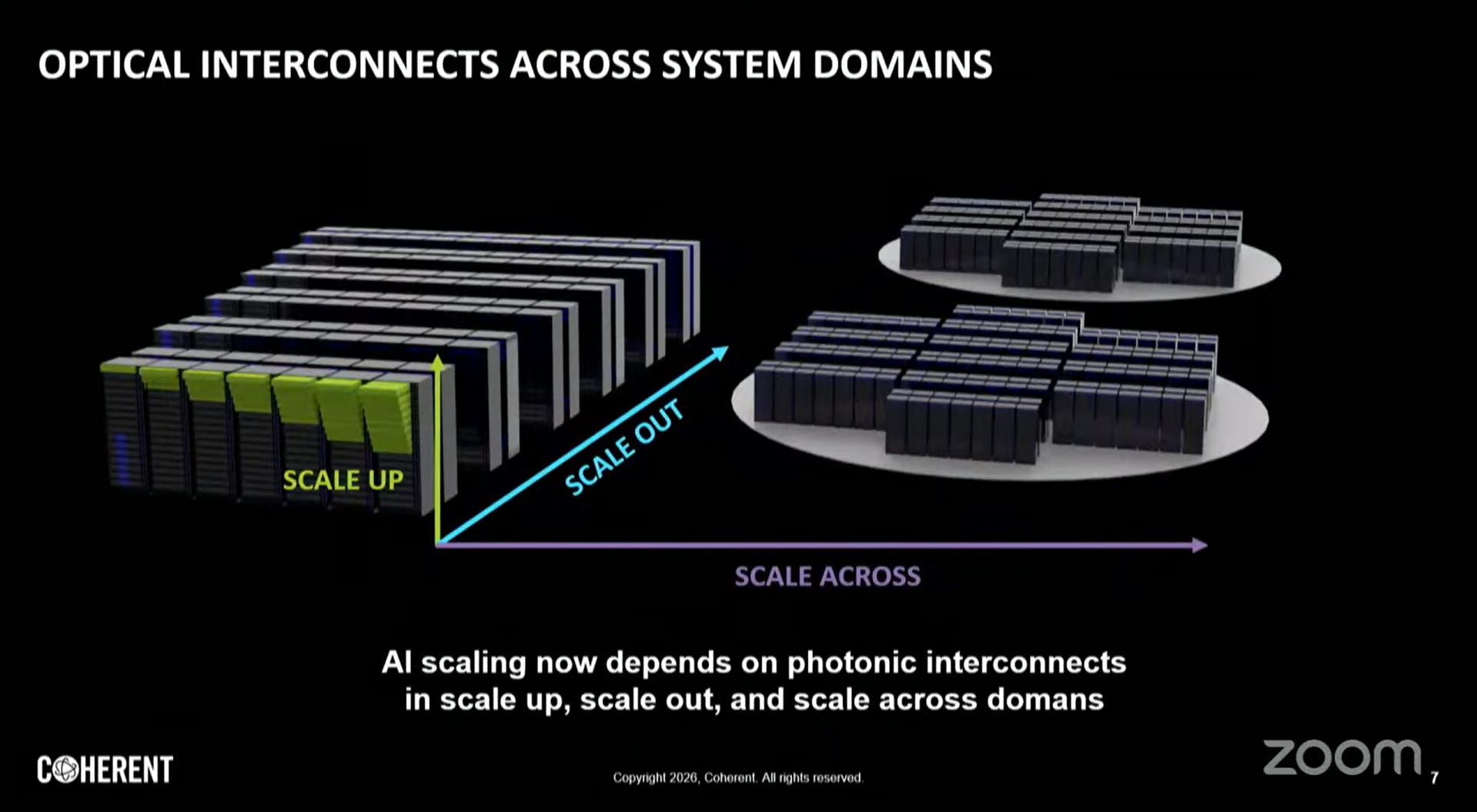
資料中心的基礎設施分為兩個座標軸:
Scale Up(縱向擴展 / 向上擴展): 指的是在單一節點或單一機櫃內部增加運算能力。這涉及 GPU 與 GPU 之間、或者 CPU 與加速器之間的極高速通訊。其目標是讓多個處理器看起來像「一顆巨大的邏輯電腦」。
Scale Out(橫向擴展 / 向外擴展): 指的是將多個伺服器機櫃(Racks)連接在一起形成大型集群。其目標是通過增加節點數量來提升整體的吞吐量與處理能力。
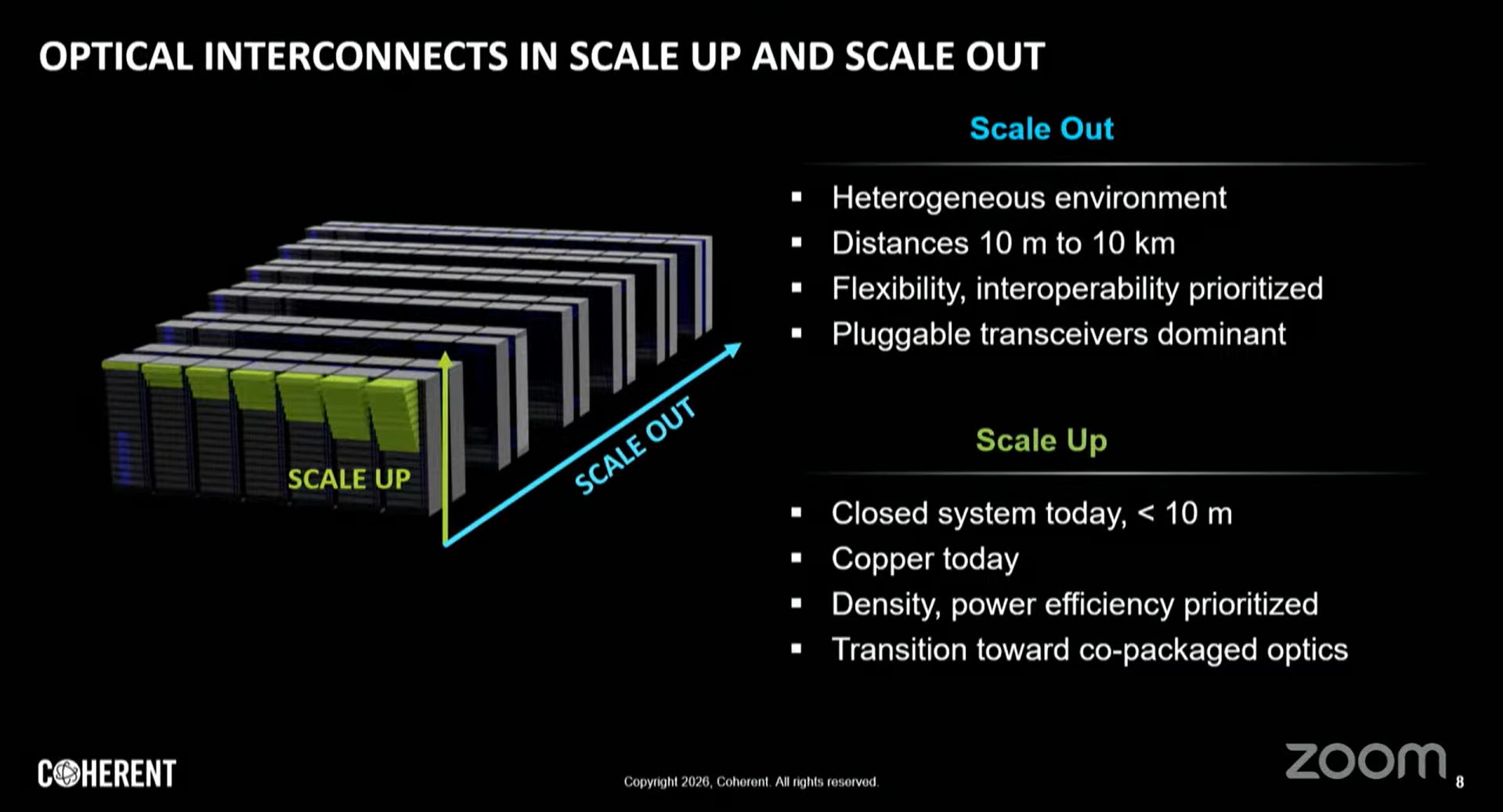
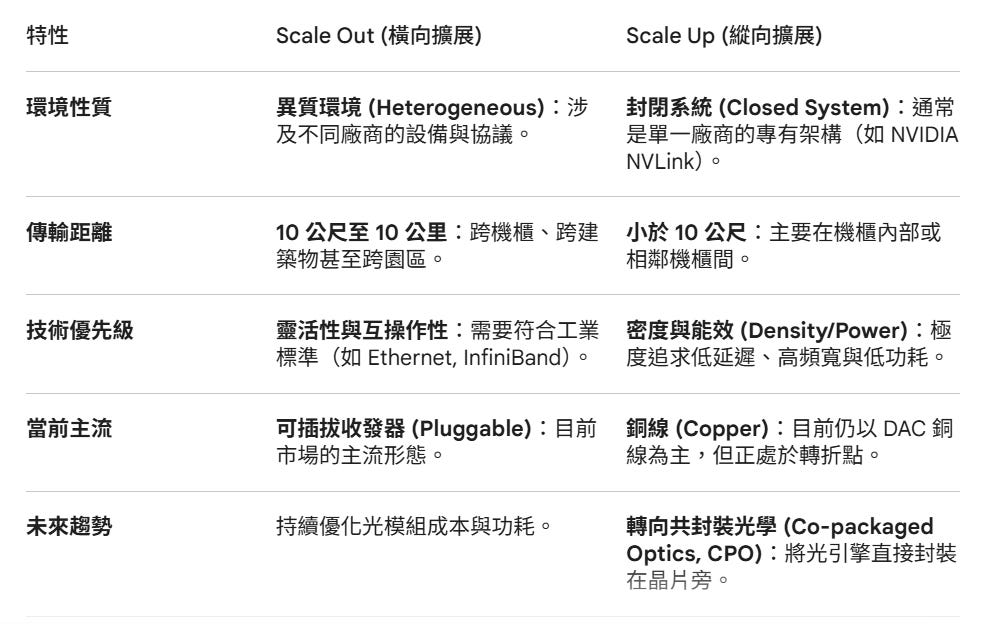
關鍵的技術演進:
光學技術的「向內滲透」
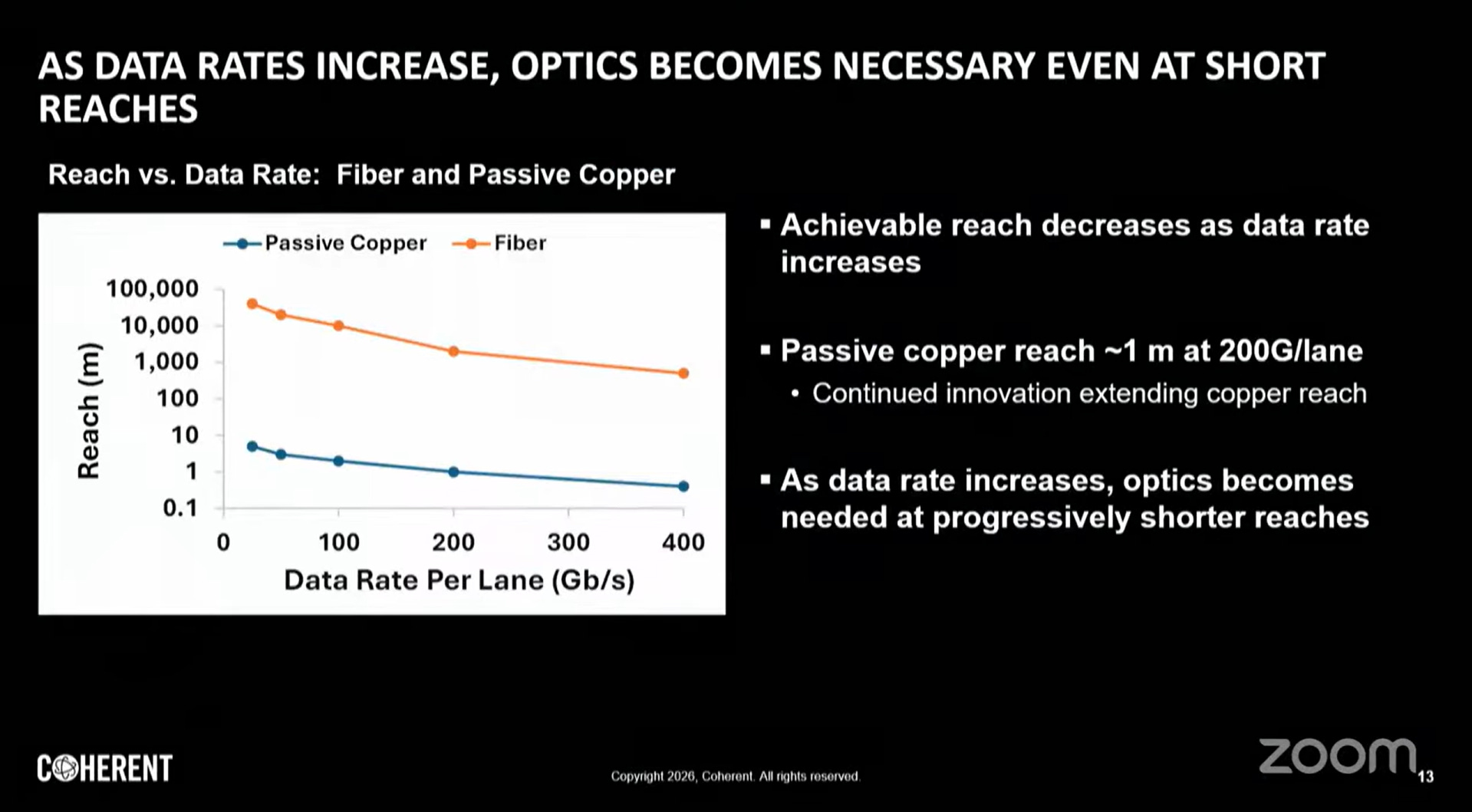
傳統上,光學互連(如光纖模組)主要用於 Scale Out(長距離傳輸)。然而,隨著 AI 算力需求暴增,Scale Up(短距離、高密度)領域正遇到「銅線瓶頸」。銅線在超過 2-3 公尺後的訊號衰減嚴重且極為笨重。
從 Copper 到 CPO 的轉型
圖中特別提到 Scale Up 正在從「Copper today」轉向「Co-packaged optics」。這意味著為了維持 AI 集群內部的極速互連(例如 GPU 叢集的線性擴張),光學技術必須進入機櫃內部,甚至直接封裝在處理器旁邊,以解決散熱、空間限制與功耗問題。
四、Scale Out域:可插拔收發器技術生態
Scale Out域因設備異質性、鏈路距離跨度(10公尺至10公里)及多廠商互通性需求,可插拔收發器仍是主流解決方案。

1. 可插拔收發器的核心價值:靈活性
上半部強調了可插拔模組(如我們常見的 SFP, QSFP, OSFP 等)之所以成為業界主流,主要源於以下三個特性:
標準化與多供應商生態系統: 遵循 MSA(多源協議)標準,確保不同廠商的設備(如 Cisco 的交換器配上 Coherent 的光模組)能互通,降低供應鏈風險與成本。
易於維護與服務: 當單一光鏈路出現故障時,只需拔出模組更換,無需拆解整台交換器或影響其他埠位。
延遲架構承諾(Defers Architectural Commitment): 營運商可以先採購交換器主機,等實際流量需求產生時再購買對應速率的光模組,優化資金配置。
2. 物理結構剖析
圖片右下方展示了光收發器的內部構造,這是一個高度整合的微型光電系統,包含:
Integrated Circuits (IC): 包含 DSP(數位訊號處理)或驅動晶片,負責電信號的處理與補償。
Detectors (偵測器): 將接收到的光訊號轉回電訊號。
Source Lasers (光源雷射): 產生攜帶數據的光脈衝。
Passive Optics (被動光學元件): 包含透鏡、稜鏡等,用於耦合與導引光路。
3. 面臨的技術瓶頸:頻寬密度
下半部提出了一個關鍵論點:「交換器頻寬受到收發器頻寬密度的限制。」
隨著 AI 算力需求爆炸,交換器晶片(Switch ASIC)的總頻寬(例如 51.2T 或 102.4T)提升極快,但受限於實體面板空間:
每通道數據率(Per-lane data rate): 需要從 100G 往 200G 甚至更高演進。
收發器通道數(Lanes per transceiver): 在有限的空間內擠入更多通道,會帶來嚴重的散熱與訊號完整性挑戰。

主要光引擎技術對比
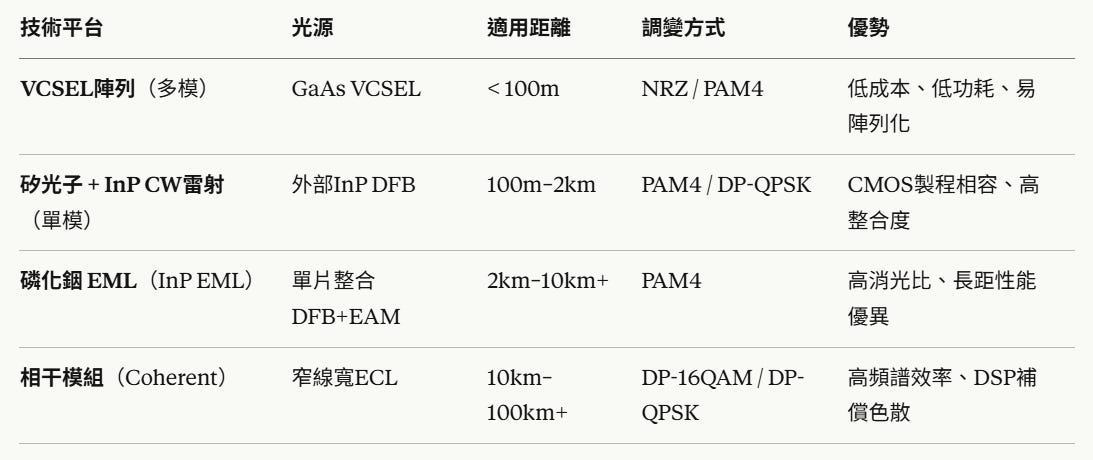

400G/lane面臨的物理制約
每通道擴展至400G(約112Gbaud PAM4或56Gbaud DP-QPSK)面臨多重傳輸限制:
色度色散(Chromatic Dispersion, CD):單模光纖標準色散係數約17ps/(nm·km),高波特率訊號脈衝展寬嚴重,超過一定傳輸距離需主動色散補償(DCM)或電域DSP均衡。
偏極模態色散(Polarization Mode Dispersion, PMD):訊號在光纖中因雙折射效應造成差分群延遲(DGD),對高速訊號形成碼間干擾(ISI)。
訊雜比容限(OSNR Margin):PAM4調變相比NRZ需要更高的光訊雜比(OSNR),縮短無中繼傳輸距離,超過30km以上需採用相干調變搭配數位訊號處理(DSP)。
增加並行通道數(Lane Count)是提升聚合頻寬的主要途徑,但帶來封裝複雜度、纖芯陣列對準精度(Fiber Array Alignment)與光纖扇出(Fan-Out)管理的工程挑戰。

技術挑戰
每通道擴展至400G面臨多重限制:
色散(Dispersion):高速訊號在光纖中傳播時,不同頻率成分速度差異造成脈衝展寬,限制傳輸距離
訊雜比(SNR)限制:PAM4調變對接收靈敏度要求高,長距離需色散補償或相干調變
相干調變(Coherent Modulation):採用DP-QPSK或DP-16QAM,搭配數位訊號處理(DSP),可大幅延伸傳輸距離,但功耗與成本相應增加
增加通道數(Lane Count)是提升聚合頻寬的主要路徑,但也帶來封裝複雜度、散熱設計與光纖管理的挑戰。
五、進階可插拔外形規格的興起

為因應AI叢集對更高密度的需求,新型插拔規格相繼問世:
XPO(含整合液冷)
整合水冷模組,解決高功耗散熱瓶頸
支援 12.8 Tbps(64通道 × 200G/通道)
適合高密度機架部署
OIF高密度外形規格
目標 25.6 Tbps(採用400G/通道)
由光互連論壇(OIF)主導標準化,確保多廠商互通
技術補充:傳統QSFP-DD與OSFP規格在功耗上限(約15–20W)已趨近瓶頸。新形規格透過改善熱管理(液冷、導熱介面材料)突破此限制,但同時要求機架基礎設施(CDU, Coolant Distribution Unit)相應升級。
六、Scale Up域:共封裝光學(CPO)

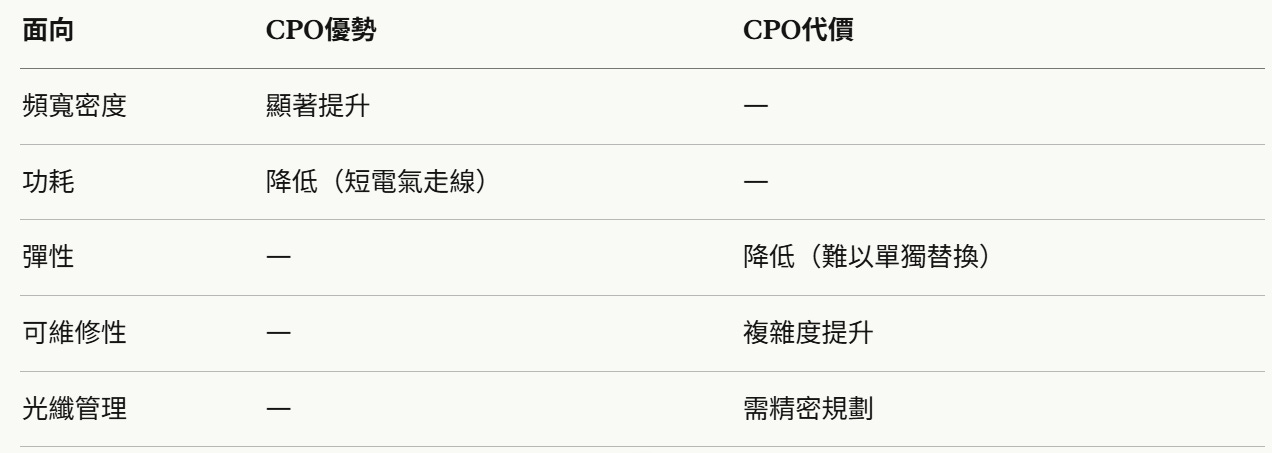
共封裝光學(CPO, Co-Packaged Optics)是針對Scale Up域高密度需求的架構性重構——將光引擎移至緊鄰交換器(Switch)或加速處理器(XPU)的位置。
可插拔 vs CPO 架構對比

CPO的優勢與代價
CPO變體
近封裝光學(NPO, Near-Packaged Optics):光引擎位於封裝外但緊鄰,兼顧密度與可維護性
插座式CPO(Socketed CPO):光引擎可獨立更換,提升維修彈性
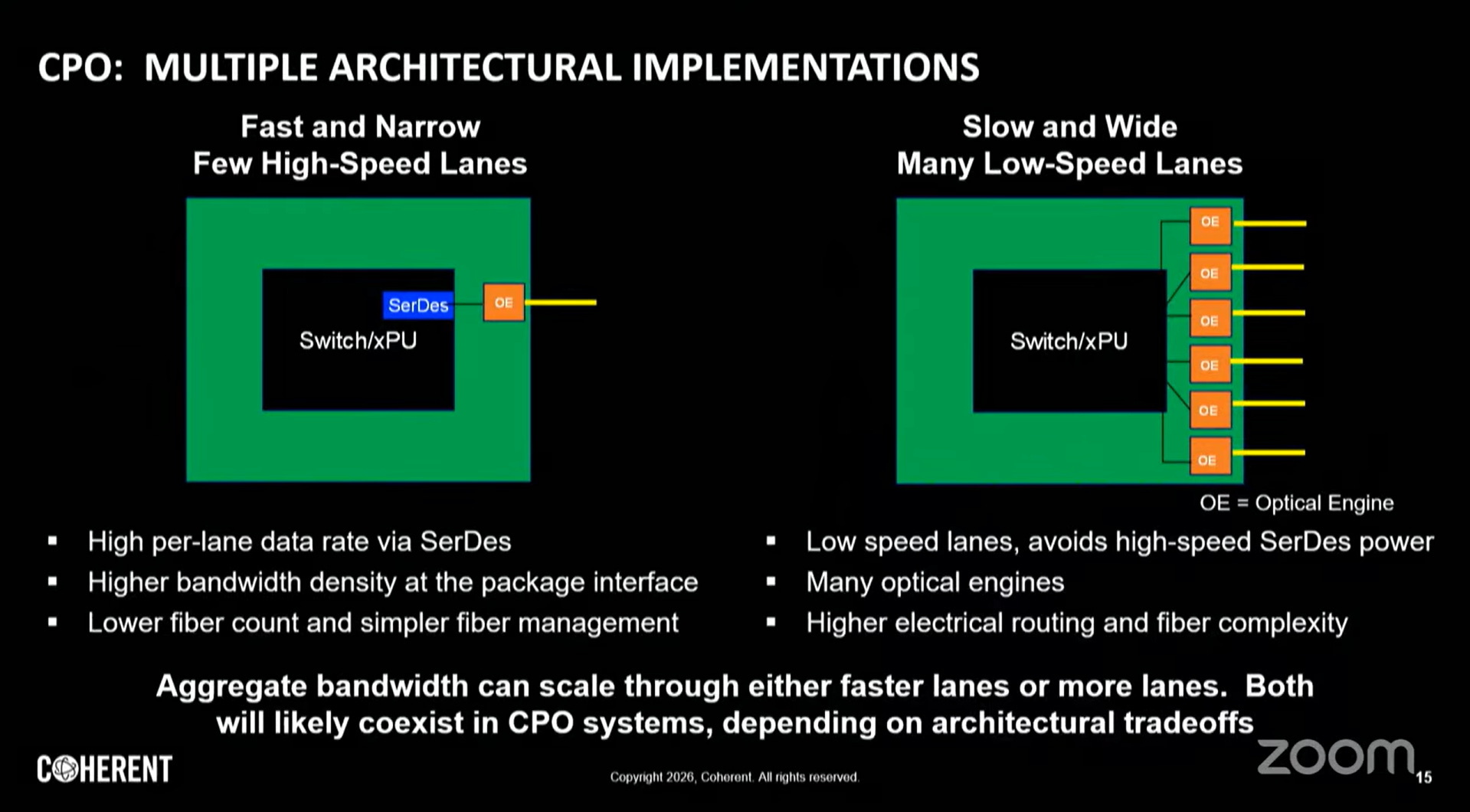
快窄架構(Fast-and-Narrow):高波特率、少通道,SerDes功耗高但佔位小
慢寬架構(Slow-and-Wide):低波特率、多通道,串擾管理複雜但功耗較低
七、CPO技術實現路徑

多種技術路線並行發展,各有其最適應用場景:
矽光子 + 遠端可插拔連續波雷射(CW Laser) 利用外部雷射源(通常為InP)透過光纖耦合進入矽光子晶片,規避矽光子難以直接整合雷射的材料限制。適合大規模量產,成本具競爭力。
砷化鎵(GaAs)VCSEL型CPO 針對極短距(< 2m)、低功耗場景優化,適合節點內XPU間直連。製程成熟、成本低。
微型LED(Micro LED) 新興方案,功耗極低,適合超短距離高密度互連,技術成熟度仍在提升中。
磷化銦馬赫-曾德爾調變器(InP MZM)+ 整合半導體光放大器(SOA) 提供高調變頻寬與訊號增益補償,適合中距離高速率需求,但製造複雜度較高。
八、光電路交換(OCS)與熱管理擴展

光電路交換(OCS)
OCS作為AI工作負載的架構工具重新受到重視,其核心價值在於軟體定義拓撲重組(Software-Defined Topology Reconfiguration):
根據AI訓練任務動態調整XPU間的連接關係
提升XPU利用率(減少因拓撲固定造成的資源閒置)
增強網路韌性(路徑冗餘與故障繞道)
主要實現技術:

目前已有 320×320 規模的量產系統部署於AI資料中心。
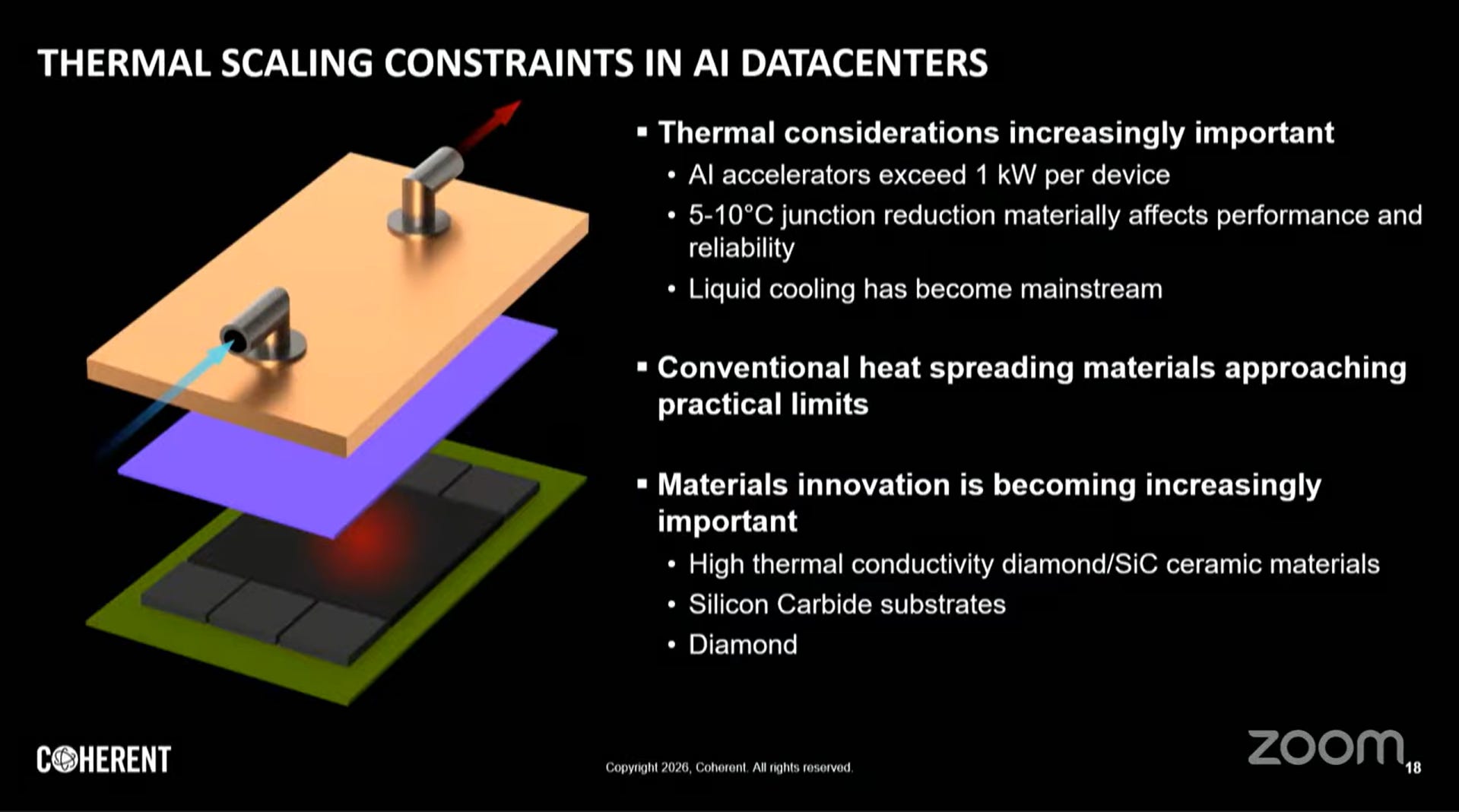
熱管理挑戰
AI 加速器功耗已進入千瓦級(Kilowatt-class)時代(如 NVIDIA GB200 NVL72 機架總功耗超過 100kW),帶來嚴峻的熱管理挑戰:
液冷技術:直接液冷(Direct Liquid Cooling)、浸沒式冷卻(Immersion Cooling)
先進散熱材料:
鑽石(Diamond):熱導率超過2000 W/m·K,用於高功耗元件的熱擴散層
碳化矽(SiC):熱導率約490 W/m·K,兼具機械強度,適合封裝基板
控制接面溫度(Junction Temperature)對於光學元件的壽命與效能至關重要,波長漂移與輸出功率均對溫度高度敏感。
九、Scale Across:資料中心互連(DCI)
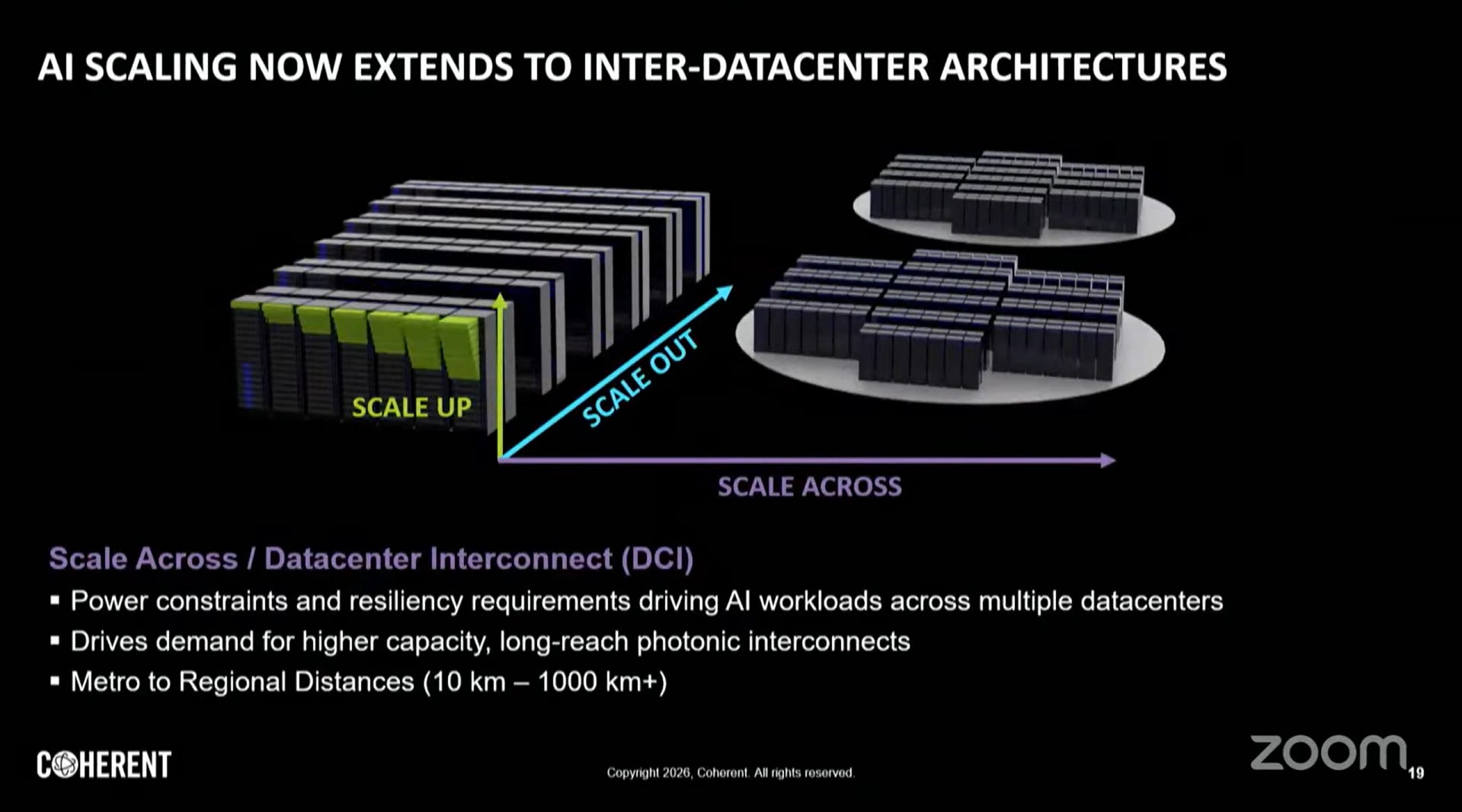
跨資料中心網路(DCI)距離跨越10至超過1,000公里,AI工作負載對其提出更高的容量與韌性要求。
頻譜效率的物理極限
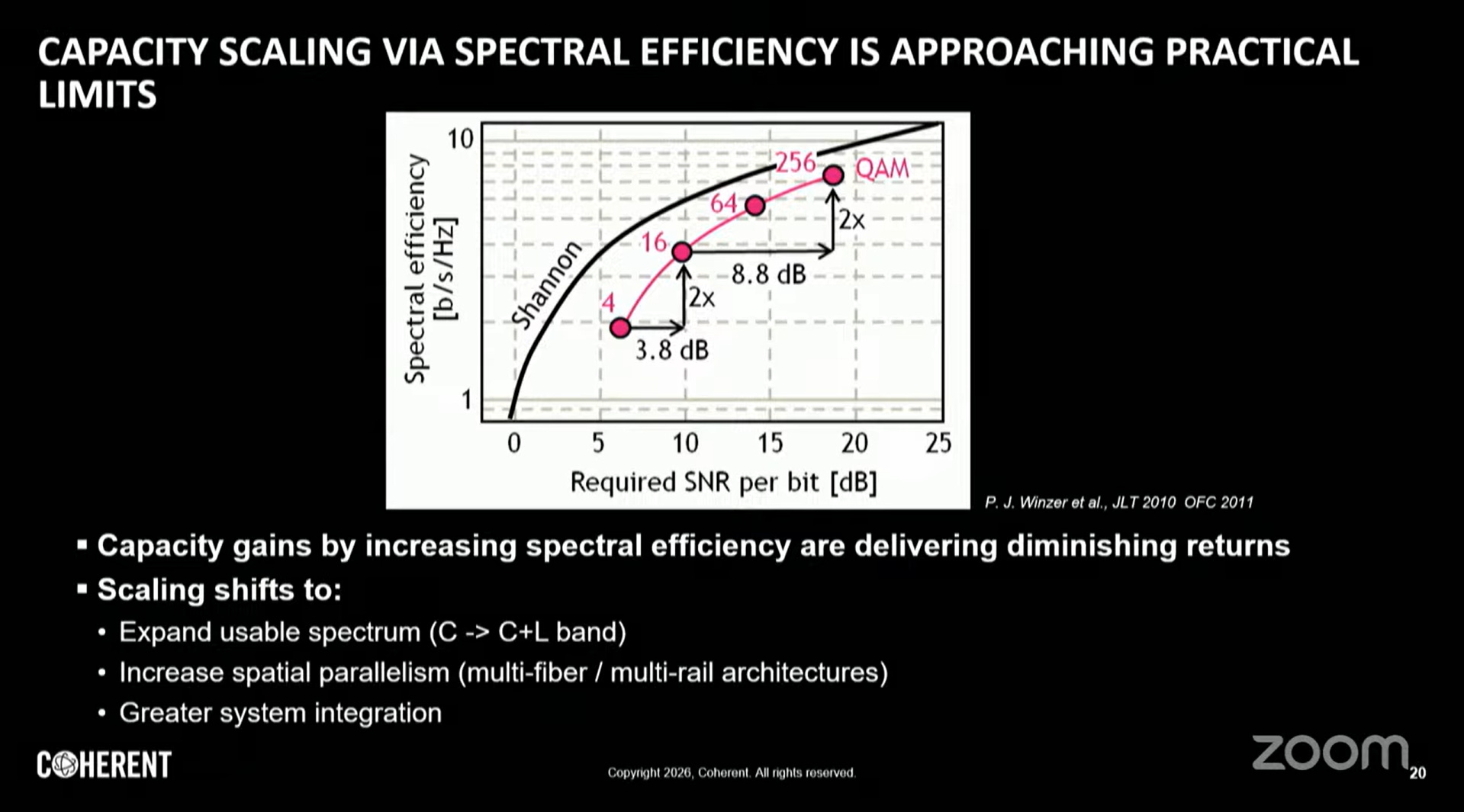
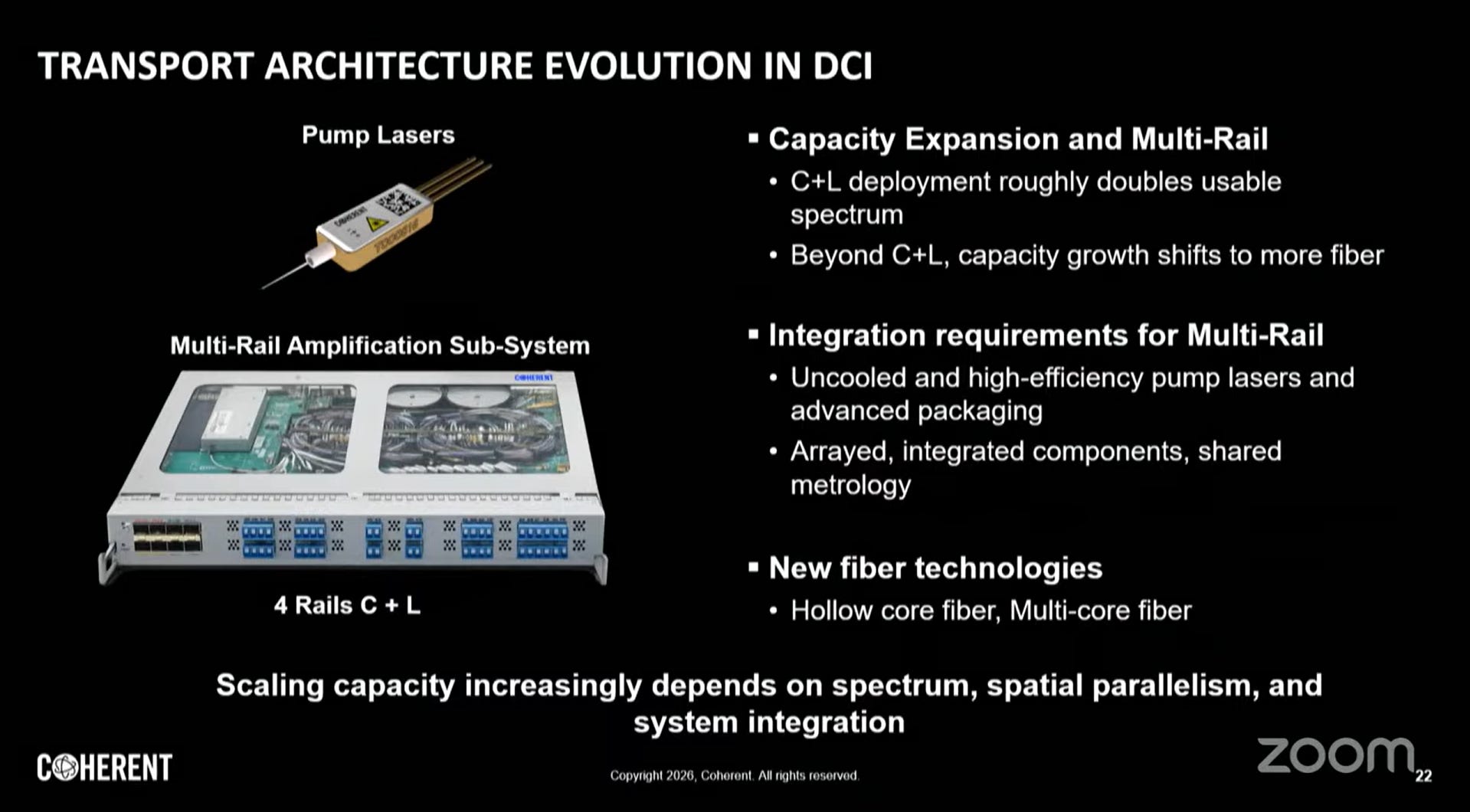
隨著訊雜比(SNR)逼近香農極限,頻譜效率提升空間收窄,擴展策略轉向:
1. 擴展頻譜(C+L Band)
C波段(1530–1565nm)+ L波段(1565–1625nm)
可用頻寬幾乎翻倍,搭配寬頻EDFA實現
2. 空間並行(Spatial Parallelism)
多芯光纖(Multi-Core Fiber, MCF):單根光纖包含4–12個獨立纖芯
空芯光纖(Hollow Core Fiber, HCF):光在空氣中傳播,延遲降低約30%(接近光速),損耗更低
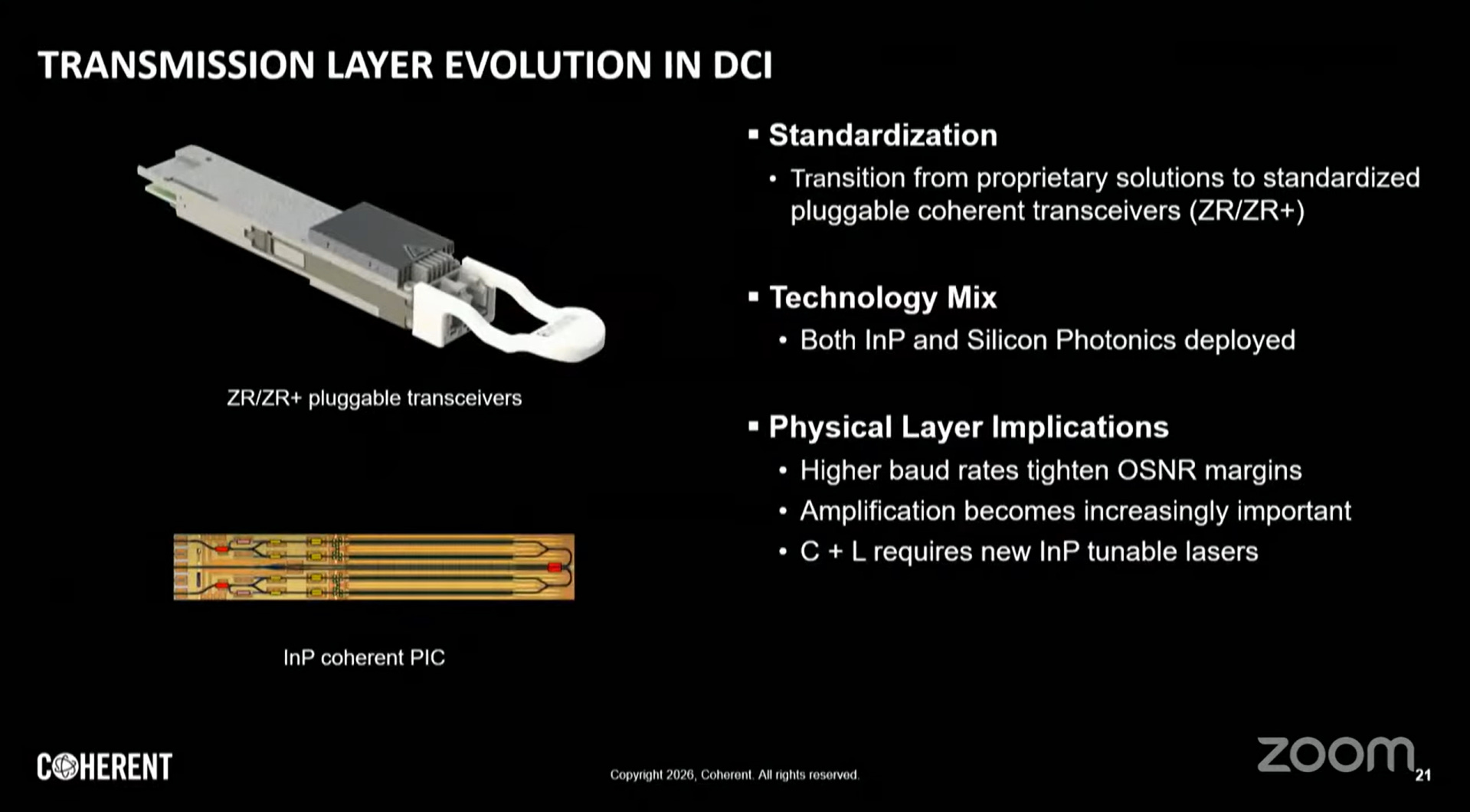
3. 可插拔相干收發器
ZR(400ZR):80km無中繼,標準化介面,適合城域互連
ZR+:採用更高階DSP,延伸至1000km+,支援更高調變格式
4. 放大器技術
半導體光放大器(SOA):體積小、可整合,適合短距補償
摻鉺光纖放大器(EDFA):長距主力,噪聲指數低
5. 多軌架構(Multi-Rail Architecture) 透過路徑多樣化提升韌性,AI訓練任務對網路中斷極為敏感,任何封包遺失皆可能導致訓練作業重啟。
十、結語:光學成為AI擴展的核心

擴展需求正在加劇,物理極限同步收緊。沒有任何單一光學技術能滿足所有需求;多元解決方案分別服務不同的架構約束。光學已內嵌於算力架構之中,未來AI系統的擴展將愈來愈依賴光學領域的快速創新。
這一論述標誌著光子學角色的根本性轉變:從網路基礎設施的配套元件,進化為AI算力架構的內生組成部分。光學工程師、系統架構師與AI研究者之間的協作,將成為推動下一代AI系統突破的關鍵介面。