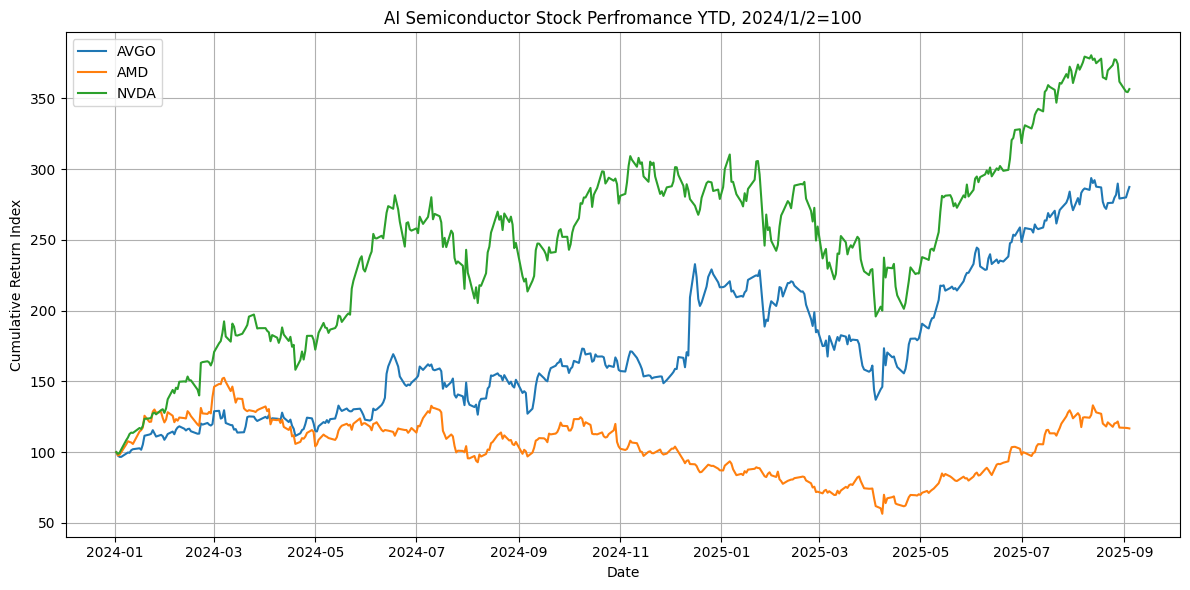
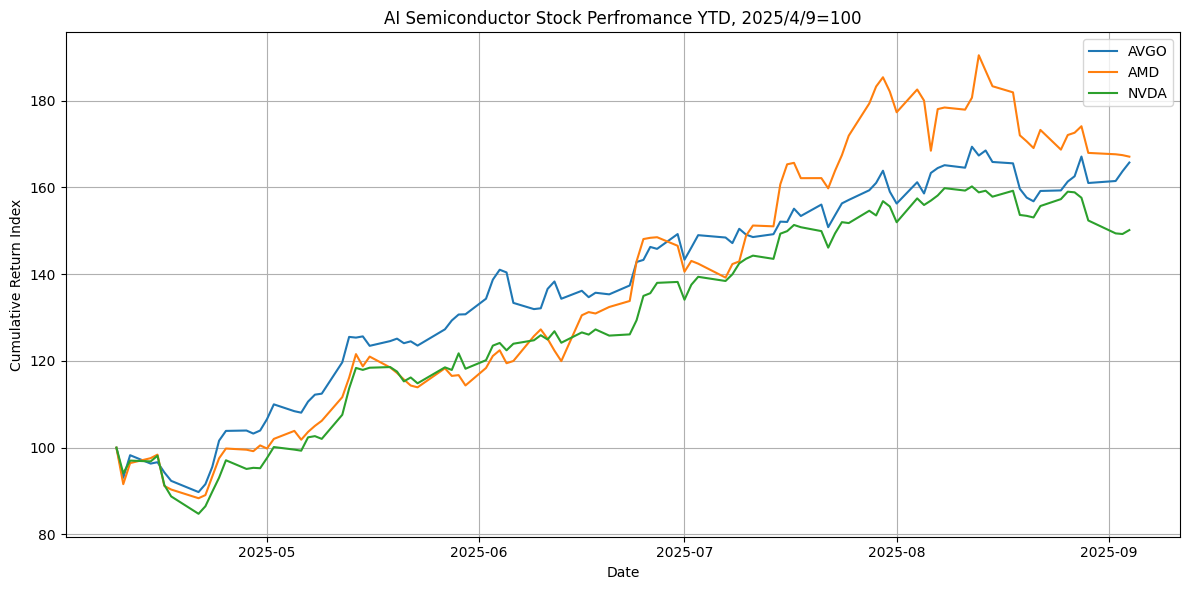
AI 應用落地帶動收益增長
AI 技術正從實驗室走向商業化,直接成為科技巨頭核心業務增長的引擎。以 Alphabet(Google 母公司)的最新財報為例,各項業務都因 AI 加持而收益提升:

Google Search 廣告:2025 年第2季「Google 搜尋與其他」營收達 542 億美元,年增 12%。這不再只是傳統的關鍵字配對收益,AI 搜尋生成摘要(SGE)等功能提升了用戶查詢量(相關 AI 摘要讓全球查詢額外增加逾 10%),也透過更精準的點擊率預測與排名算法提高廣告投放效率,帶來實質營收成長。
YouTube 廣告:得益於強大的 AI 推薦系統(包括對影片內容的多模態理解),YouTube 提供高度個人化的內容與廣告,增加用戶停留時間並提升廣告精準度。YouTube 廣告收入在第2季達 98 億美元,年增長 13%,印證了推薦演算法對業績的拉動作用。
Google Cloud 雲端服務:雲端業務是 AI 基礎設施商品化的直接體現。Google Cloud 第2季營收達 136 億美元,年增長 32%。這包含提供 TPU/GPU 算力租賃、Vertex AI 平台以及生成式 AI 模型(如 Gemini)的 API 服務等。企業對 AI 基礎設施和平台的強勁需求,讓 Google Cloud 成為 Alphabet 極重要的增長引擎,32% 的高速成長率正是持續投入 AI 的回報。
Google Play 及設備:AI 能力正從雲端延伸至終端裝置。以 Pixel 手機為例,其搭載的 Magic Eraser 照片魔擦、即時翻譯等 AI 功能提升了產品附加價值,成為裝置差異化的關鍵賣點,助力該季度「Google Play 和裝置」業務實現 112 億美元收入(包含硬體、應用商店等)。AI 技術使得傳統硬體產品更具智慧化,也帶動了生態系服務的收入。
總的來說,AI 正在從實驗性的技術熱點轉化為商業世界的實質收益來源。Alphabet 的例子清楚表明,大模型等 AI 技術深入核心產品後,能直接反映在營收增長上。
算力霸權轉變:從 GPU 到機櫃級系統的戰爭
當前這波 AI 浪潮的本質,是對算力(Compute)的無限追求。為了滿足訓練數千億乃至兆億參數模型的需求,產業正從單機 GPU 發展到整櫃的超大規模系統。NVIDIA 身為通用 GPU 的霸主,也調整了策略:從銷售單顆晶片轉向機櫃級系統方案。

整櫃超級GPU 的崛起:NVIDIA 在 2024 年 GTC 大會推出的新一代 Blackwell 架構,強調的就是整櫃解決方案。以基於 Blackwell 的 GB200 NVL72 系統為例,它在一個機櫃中整合了 72 顆 GPU,透過高速 NVLink 互連把整櫃伺服器視作一顆巨型 GPU。NVIDIA 執行長黃仁勳更直言,未來「他心目中的 GPU 就是一整櫃 NVL72」。這套統一設計的液冷機櫃提供高達 13,824 GB 的總顯存和極寬的頻寬,對訓練超大規模模型至關重要。
從單卡銷售到整櫃溢價:賣整櫃系統也讓 NVIDIA 獲得前所未有的定價權。傳統而言,一台搭載 8 顆 H100 GPU 的伺服器售價約數十萬美元(H100 卡單價約 $30K 級別)。而一櫃含 72 顆 Blackwell GPU 的 NVL72 系統售價可達 300 萬美元。NVIDIA 更傾向直接販售整櫃而非單卡,吸收原本屬於系統整合商的價值,提高自身營收與利潤。換言之,NVIDIA 正將價值鏈從晶片擴張到整個機櫃,透過一條龍方案穩固利潤來源。
性能與擴展性:機櫃級系統的採用,根本原因在於單機性能已趨近極限。訓練兆億參數的模型需要超高計算密度和互聯帶寬,傳統單台伺服器無法滿足。NVL72 將 72 顆 GPU 嚴密連接成一體,使其吞吐量提高數十倍(NVIDIA 宣稱對比上一代系統實現 30 倍以上的推理性能提升),能滿足實時大模型推理與巨量並行計算的需求。
數據中心效率提升:整櫃解決方案還能大幅改善能效和空間利用率。如今超大規模數據中心從過去每機櫃 20kW 的標準躍升到每機櫃高達 135kW。如此高的功率密度只能靠直接液冷。NVIDIA 與 Vertiv 等廠商合作開發了液冷架構,使 GB200 NVL72 系統的能耗降低 25%、機櫃空間節省 75%。例如,每個 132kW 的 NVL72 機櫃年冷卻成本可節省高達 25 倍。整櫃系統讓所謂「AI 工廠」的部署更加高效,在相同空間內部署遠超以往的算力。
供應鏈價值重分配:這個策略轉變也重塑了整個供應鏈的價值分配:
GPU 模組成本:新一代 Blackwell GPU 的售價大幅攀升。據分析師估計,雙 B200 GPU 加一顆 Grace CPU 組成的 GB200 超級芯片售價高達 6–7 萬美元,比 Hopper 世代 H100 的單卡價格區間(約 3 萬美元出頭)翻倍。NVIDIA 藉由整合更多功能,成功提升了平均售價,反映在 H100 超過 90% 的毛利率上。這意味著 NVIDIA 在晶片上的定價權已達頂峰。
HBM 記憶體:高頻寬記憶體成為 AI 硬體中最昂貴的組件。以 H100 為例,拆解顯示其生產成本約 $3000,其中 HBM 記憶體就占了一半(~$1500)。Blackwell GPU 配備的 HBM3e 更大更多,單卡記憶體成本可能逼近 $3000 甚至更高。隨著 AI 對 HBM 需求爆炸式增長,SK Hynix 等 HBM 供應商成為最大受益者。SK Hynix 預期未來數年 HBM 市場每年成長 30%,2030 年達數百億美元規模。
高速銅互聯組件:在整櫃系統中,為了讓 72 顆 GPU 高效通信,NVIDIA 使用了專門的 NVLink 背板(大量高速銅纜和連接器)。這些互聯元件的成本暴增,從單機時期每單位幾百美元提升到整櫃級別的幾千美元級別,增幅達 10 倍。例如,Amphenol (APH) 是 NVIDIA NVLink 連接器主要供應商之一,其產品隨著 NVL72 的部署價值飆升。值得注意的是,NVL72 的銅質背板不僅昂貴,還出現了一些可靠性挑戰,需要經過長時間老化測試才能交付,可見其技術複雜性和關鍵程度。
散熱處理:功耗大幅提升也推高了散熱與供電的成本。以空冷伺服器為例,每卡散熱成本或許只占數百美元,而 NVL72 液冷系統每張 GPU 所需的冷 plates、泵、換熱器等可能達上千美元。Vertiv(VRT)等數據中心基礎設施供應商與 NVIDIA 合作,推出面向 NVL72 的參考冷卻方案,可支撐每櫃高達 132kW 的負載。Vertiv 表示其方案能將年能耗降25%、佔地減少75%,足見熱管理在新架構中的重要性。對供應鏈而言,散熱與供電相關的廠商在 AI 時代迎來新機遇。
透過掌控系統設計,NVIDIA 將價值鏈從晶片延伸到整櫃,進一步鞏固了生態系統的領導地位。在「算力為王」的競賽中,NVIDIA 選擇以整體解決方案來滿足無止境的算力需求,確保自身霸權難以撼動。
ASIC 的崛起:巨頭們的反擊與供應鏈新平衡
儘管 NVIDIA 在通用 GPU 市場一家獨大,超大規模雲服務商和前沿 AI 實驗室並不滿足於完全受制於單一供應商。他們開始尋求客製化 AI 晶片 (ASIC) 路線,以針對自身業務場景優化性能和成本,同時避免被鎖定。在這波 ASIC 浪潮中,Broadcom 扮演了黃金賦能者的角色。
Broadcom 的「技術總包商」策略:Broadcom 並未試圖推出通用 GPU 去硬碰 NVIDIA,而是充當晶片設計代工的總包,與 Google、Meta 等合作,把這些巨頭的架構理念轉化為可量產的客製 XPU 晶片。這些 ASIC 專為特定 AI 工作負載打造,例如推薦系統或大型模型推理,可以比通用 GPU 便宜 75%、功耗低 50%。對雲服務商而言,使用定制晶片意味著在大規模部署時能大幅節省總擁有成本(TCO)。Broadcom 背靠自身在網路晶片和ASIC設計的深厚經驗,再加上收購 VMware 帶來的軟體融合能力,提供從硬體到軟體的一攬子方案,成為巨頭們打造自有晶片的理想夥伴。
開放生態的力量 vs. NVIDIA 封閉生態:Broadcom 推出的方案強調開放標準接口,例如基於以太網的Scale-Up Ethernet (SUE) 架構。相比之下,NVIDIA 的 NVLink/NVSwitch 互聯和 CUDA 生態比較封閉。Broadcom 的非獨佔模式賦予客戶更大技術自主權和議價空間,避免被單一供應商鎖死。對雲廠商而言,Ethernet 為基礎的架構更易於整合現有數據中心,並可靈活選擇不同供應商組件,這正是 Broadcom 吸引超大客戶的賣點之一。
OpenAI 的選擇:2025 年傳出最震撼的消息莫過於 OpenAI 也走上自研晶片之路。Broadcom 公佈拿下來自一個新客戶 OpenAI 的 100 億美元 ASIC 大單。這筆訂單將在 2026 年開始貢獻 AI 晶片收入。這意味著 OpenAI 將獲得專為其模型量身打造的加速器,用於滿足如 ChatGPT 等產品日益巨大的推理需求。OpenAI 此舉被視為在追求算力獨立,以降低對 NVIDIA GPU 的依賴,以及避免受制於 AMD 或其他現貨供應商。消息傳出後,AMD 股價應聲下挫超過 5%;市場解讀為,在尋找 NVIDIA 替代方案時,超大規模用戶寧可選擇與 Broadcom 合作研發ASIC,也不會大舉轉單給 AMD 的通用 GPU。換言之,OpenAI 自研晶片「犧牲」的對象不只是 NVIDIA,還包括了寄望分一杯羹的 AMD。
巨頭紛紛自研,加速 ASIC 浪潮:OpenAI 並非孤例,其他科技巨頭近年也在加碼投入自研或客製化 AI 晶片:
Google:早在 2016 年即推出 TPU(Tensor Processing Unit)專用晶片,用於搜尋、廣告等核心業務的機器學習推理。目前已演進到第5代 TPU 並廣泛部署於其數據中心和 Cloud TPU 服務。Google 透過 TPU 在特定工作負載上取得比 GPU 更高的性價比,維持其 AI 應用的領先優勢。
Amazon:AWS 自研了 Inferentia 推理晶片和 Trainium 訓練晶片,在雲端提供給客戶使用。這些晶片針對雲端常見的模型優化,據稱在相應任務上性價比數倍於 GPU。Amazon 透過掌控晶片設計,不僅降低對 NVIDIA 的依賴,也打造了 AWS 雲服務的差異化功能。
Meta:臉書母公司近年也被曝投入自研 AI 加速器,用於強化其推薦演算法和內容排序等應用。Meta 的第一代自研晶片據報用於影片推薦推理,而未來產品可能涵蓋訓練加速器,目標是在元宇宙和廣告等關鍵領域建立硬體優勢。
字節跳動(ByteDance):這家中國科技巨頭(TikTok 母公司)近年低調組建了晶片設計團隊,研發專用的 AI 加速晶片。據路透報導,字節跳動曾與 Broadcom 合作開發先進的 5nm AI 晶片,計畫由台積電代工生產。雖然地緣政治因素帶來一些變數(如傳出該專案後續暫停),但字節跳動的動向顯示,為降低對 NVIDIA 等美國供應商的依賴,大型科技公司無論中外都在投入資源打造自有 ASIC。
Broadcom 抓住了這股客製化浪潮,迅速壯大其 AI 晶片業務。2025 年第3季,Broadcom 公布 AI 相關半導體收入達 52 億美元,年增 63%。該季財報同時證實來自新客戶(OpenAI)的百億訂單,預計將使 Broadcom 2026 年的 AI 業務激增。有華爾街分析師預計,到 2026 年 Broadcom 光是 AI 晶片收入就可達 330 億美元規模。由於 Broadcom 的客製晶片業務被視為對 NVIDIA 的有力補充,其股價和市值在 2024–2025 年間飆升,成為投資人眼中新的 AI 明星股之一。
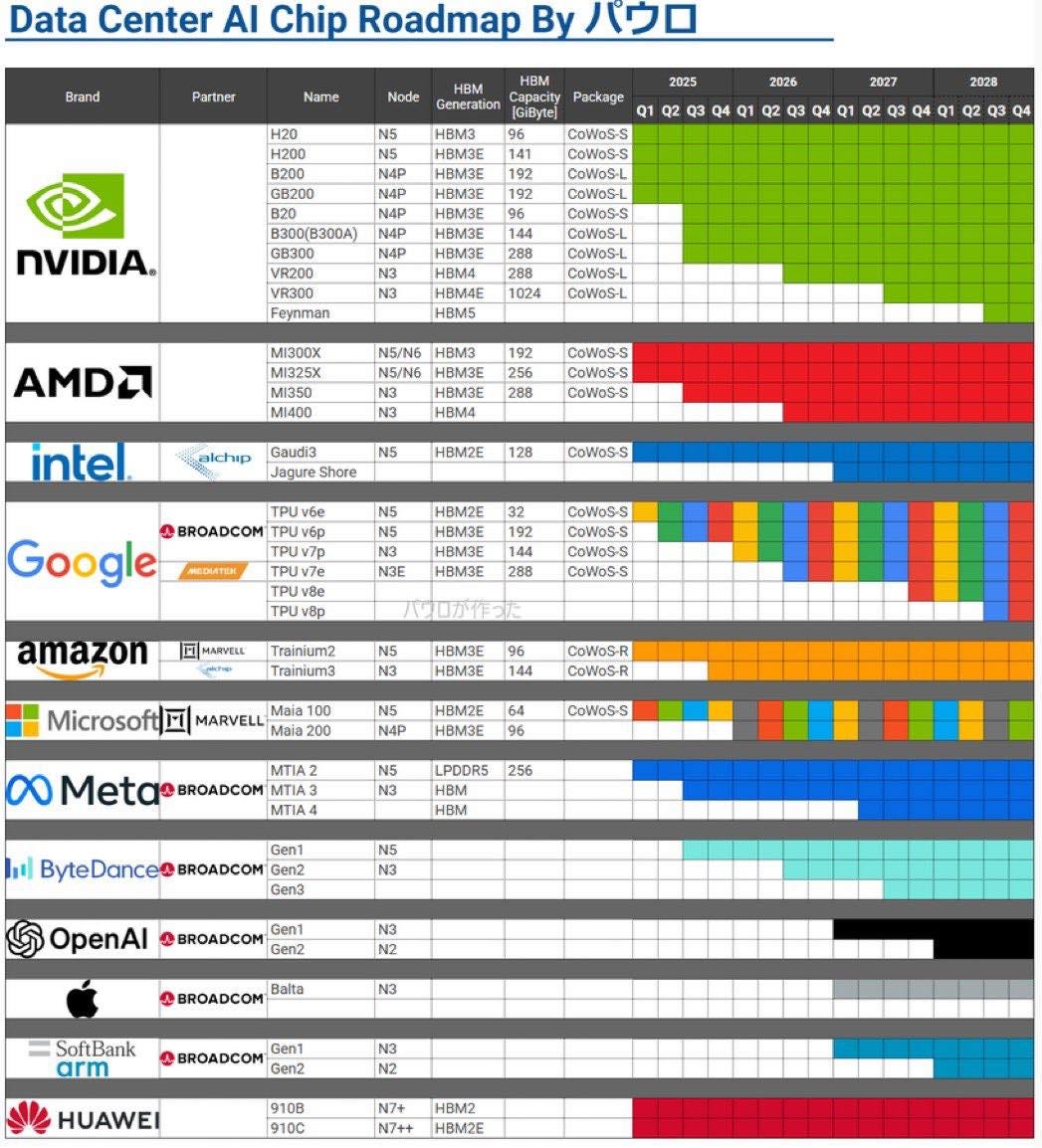
未來格局:GPU 與 ASIC 的長期共存與動態平衡
展望未來,AI 晶片市場的競爭格局很可能不是「你死我活」的單贏局面,而是 通用 GPU 與 客製 ASIC 長期共存、此消彼長的動態平衡。
NVIDIA/GPU 的持續優勢:憑藉技術和生態的雙重領先,NVIDIA 的通用型 GPU 未來仍將在大量 AI 應用中扮演主力:
市場主導地位:目前 NVIDIA 擁有 80–90% 的 AI 加速器市佔率。這一領先地位短期內難以撼動,因為 NVIDIA 已經建立起深厚的客戶基礎和供應鏈話語權。
生態體系:CUDA 軟體平台及其廣泛的開發者生態是 NVIDIA 最大的護城河。絕大多數 AI 算法和框架已對 NVIDIA GPU 進行了優化,開發者習慣其工具鏈。這種網絡效應使得競爭者很難滲透企業和開發者社群。
持續研發迭代:NVIDIA 每隔 1~2 年推出新架構(如 Hopper H100、Blackwell B100/B200 等),不斷提高性能和能效,比對手保持一代以上優勢。同時 NVIDIA 積極與前沿 AI 實驗室合作(如與 OpenAI、Meta 等共同優化軟硬體),確保新產品貼合最新需求。強大的產品路線圖和研發投入,將使 NVIDIA 在「訓練」等高端通用場景繼續主導。
競爭對手進展緩慢:AMD、Intel 等雖然發布了 MI300、Gaudi 3 等加速器,但市場反應有限,生態也不成熟。截至 2025 年,幾次大型雲端採購中 AMD 難以撼動 NVIDIA 的地位(甚至在 OpenAI 客製晶片消息後,AMD 被視為潛在受害者之一)。只要競爭者在軟硬體整合和客戶拓展上進展緩慢,NVIDIA 就能繼續憑藉近乎壟斷的地位獲取高額利潤(例如 H100 定價高達 $35,000,據估計毛利率超過 90%)。
客製 ASIC 的戰略定位:客製化 AI 晶片在未來將與 GPU 形成差異化共存,主要服務於特定巨頭的特定需求:
規模效益明顯的場景:ASIC 最適合應用在業務穩定、量級巨大的場景,例如搜尋廣告、社群推薦、視頻推流等。一旦模型和需求相對穩定,巨頭們可以透過 ASIC 把單位算力成本壓到遠低於通用 GPU。在這些場景下,ASIC 部署的規模(成千上萬顆晶片)足以攤平研發成本並換取長期回報。
通用性 vs 專用性:客製 ASIC 往往針對特定算法做優化,因此靈活性不如 GPU。這意味著在研發新模型、跑各種實驗階段,仍需要依賴 GPU 提供的通用算力和成熟軟體支持。一旦模型定型且工作負載巨大,才考慮用 ASIC 接管。因此未來大多數創新領域(如新的研究模型)會先發生在 GPU 上,ASIC 則用於成熟業務的成本優化。兩者形成研發與部署的分工:GPU 探索,ASIC 收割。
Broadcom 模式的局限:Broadcom 雖然在客製 AI 晶片浪潮中扮演重要角色,但其業務高度依賴少數超大客戶,具有客戶集中度高的風險。此外,在軟體生態上,Broadcom/客製晶片遠不如 NVIDIA 豐富,需要仰賴客戶自行適配或使用開源框架。未來若 NVIDIA 開放部分技術或第三方軟體層出現支持,多元加速器共存的環境才能成熟。換言之,ASIC 的崛起也取決於產業是否建立起標準化接口(例如 OpenAI 模組、UCIe Chiplet 等)讓定制晶片融入主流架構。近期業界已組建所謂「ASIC 聯盟」,包括 AMD、Marvell 等晶片廠商共同制定開放加速器標準,以降低開發門檻。這些努力若成功,將進一步促進 ASIC 與 GPU 的協同共存。
多元玩家的機會:除了雲端巨頭自研,一些新創公司也在開發專用 AI 加速器(如 Cerebras、Graphcore、寒武紀等),主打特定性能優勢。如果他們找到利基市場,也會加入競爭行列。但長期看,能夠大規模量產並挑戰 NVIDIA 的還是那些擁有龐大數據中心需求和資本的公司。因此我們預期未來市場將呈現兩極:一極是 NVIDIA 提供的標準化解決方案覆蓋廣泛客群,另一極是少數巨頭用自研ASIC滿足內部超大規模需求,中間則是小部分其他加速器分享特殊應用市場。
總體而言,GPU 與 ASIC 在未來將形成此消彼長的動態平衡,而非你死我活。NVIDIA 繼續扮演「水電公司」角色,為絕大多數用戶提供通用算力;同時少數科技巨頭通過客製晶片建立「自備電廠」,服務自身特殊需求。兩種路線將長期共存並互相影響:NVIDIA 為維持競爭力,可能也會在產品中融入一些客製化思維(例如提供更模組化的設計供大客戶選配);而採用 ASIC 的公司也會持續評估通用 GPU 的性價比,在靈活性與成本間動態取捨。
對投資人而言,這意味著 AI 晶片市場的版圖不再由單一公司壟斷,而是生態系統競爭。既要關注 NVIDIA 這樣的通用晶片巨頭的動態,也不能忽視 Broadcom 這類幕后功臣的崛起。許多分析師認為 NVIDIA 和 Broadcom 應被視作 互補而非替代 的關係——前者引領訓練等高性能市場,後者滲透超大規模推理和客製市場,兩者都有長期成長空間。
未來幾年,AI 對算力的饑渴只會有增無減,這場由需求拉動、供應鏈各環節共同參與的競賽將持續重塑半導體產業格局。我們需要動態地從終端應用增長(需求端)、算力供給鏈價值分配(供應端),以及主要玩家策略演變(競爭端)三方面去審視,才能在瞬息萬變的 AI 時代把握產業脈動,做出明智決策。