

對於大型語言模型(LLMs),「詞元」(tokens)是模型處理文字的基本單位。當你向 ChatGPT 輸入「Hello world!」時,模型並非看到兩個單詞和一個標點符號,而是可能將其分解為四個獨立的 tokens:['Hello', ' world', '!', '\n']。
詞元(Token)主宰了大型語言模型的世界。你向模型傳送詞元,按詞元計費,而模型則閱讀、理解並依賴詞元運作。
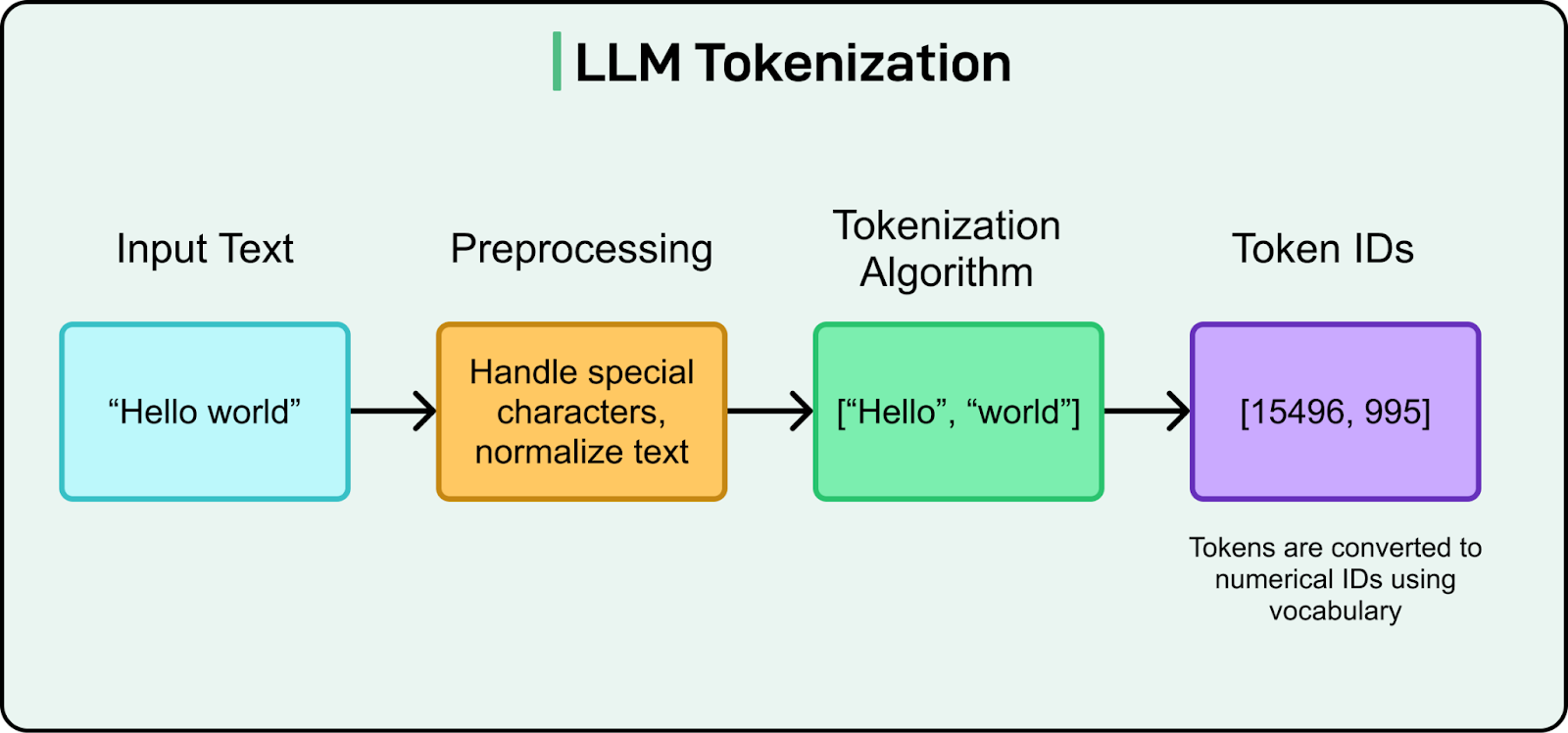
什麼是 Token?
詞元(Token)是大型語言模型(LLMs)處理文字的基本單位。然而,toekn 並不總是等同於單詞(word)。根據使用的分詞方法,詞元可能代表:
單個字符(a single character)
子詞(單詞的一部分)(a subword)
完整單詞(a complete word)
標點符號
特殊符號
空白字符
例如,句子「I love machine learning!」可能被分詞為:["I", "love", "machine", "learning", "!"]
或["I", " love", " machine", " learn", "ing", "!"],具體取決於分詞方法。
為什麼分詞很重要?
分詞在多個方面至關重要:
詞彙管理:
大型語言模型的詞彙量有限(通常為 3 萬至 10 萬個詞元)。分詞通過將罕見或複雜單詞拆分為可重用的子詞單位(例如「extraordinary」→「extra」+「ordinary」),使有限的詞彙能夠表達無限的語言空間,從而無需為每種語言的每個可能單詞分配獨立詞元。處理未知單詞:
優秀的分詞策略能將陌生單詞分解為熟悉的子詞單位,使模型能夠處理從未見過的單詞。例如,模型可能從未見過「biocatalyst」,但能識別「bio」和「catalyst」作為獨立詞元,並從中提取有用的含義。效率:
文字序列的長度直接影響計算需求。高效的分詞能減少表示文字所需的詞元數量,從而提升計算效率。模型性能:
分詞的質量影響模型對文字的理解和生成能力,特別是在非英語語言或專業領域中。分詞不當可能導致語義碎片化或結構扭曲。
詞元如何被大型語言模型處理?
文字經過分詞後,還需進一步轉化為神經網絡能夠處理的數值形式,這一過程稱為數值表示。每個詞彙中的詞元被分配一個獨特的整數ID(稱為詞元ID)。例如:
「Hello」 → token ID 15496「 world」 → token ID 995
這些token ID 隨後通過嵌入層(embedding layer)轉換為高維數值向量,稱為嵌入向量(embeddings)。每個 token ID 對應一個由實數組成的密集向量(通常為512、1024或更高維度)。例如,「Hello」可能被表示為一個向量,如 [0.23, -0.45, 0.78, ...]。
這種數值轉換是必要的,因為神經網絡只能對數字進行數學運算,而無法直接處理文字符號。嵌入向量(embedded vectors)捕捉了詞元之間的語義關係,相似的 tokens 在高維空間中具有相似的向量表示。這使得模型能夠「理解」「king」和「queen」的關聯,或「run」和「running」的語義相似性。

常見 Tokenization 方法
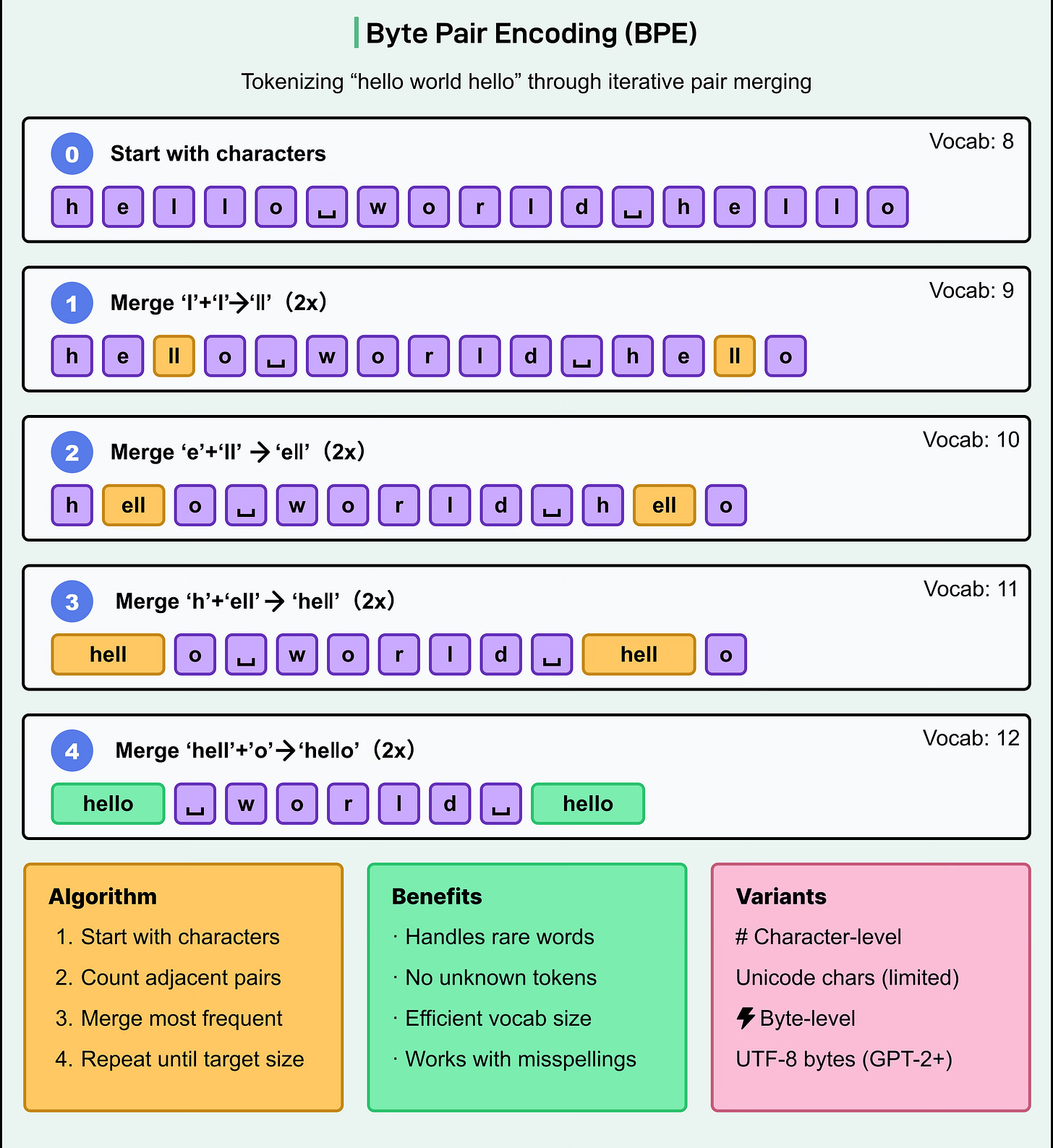
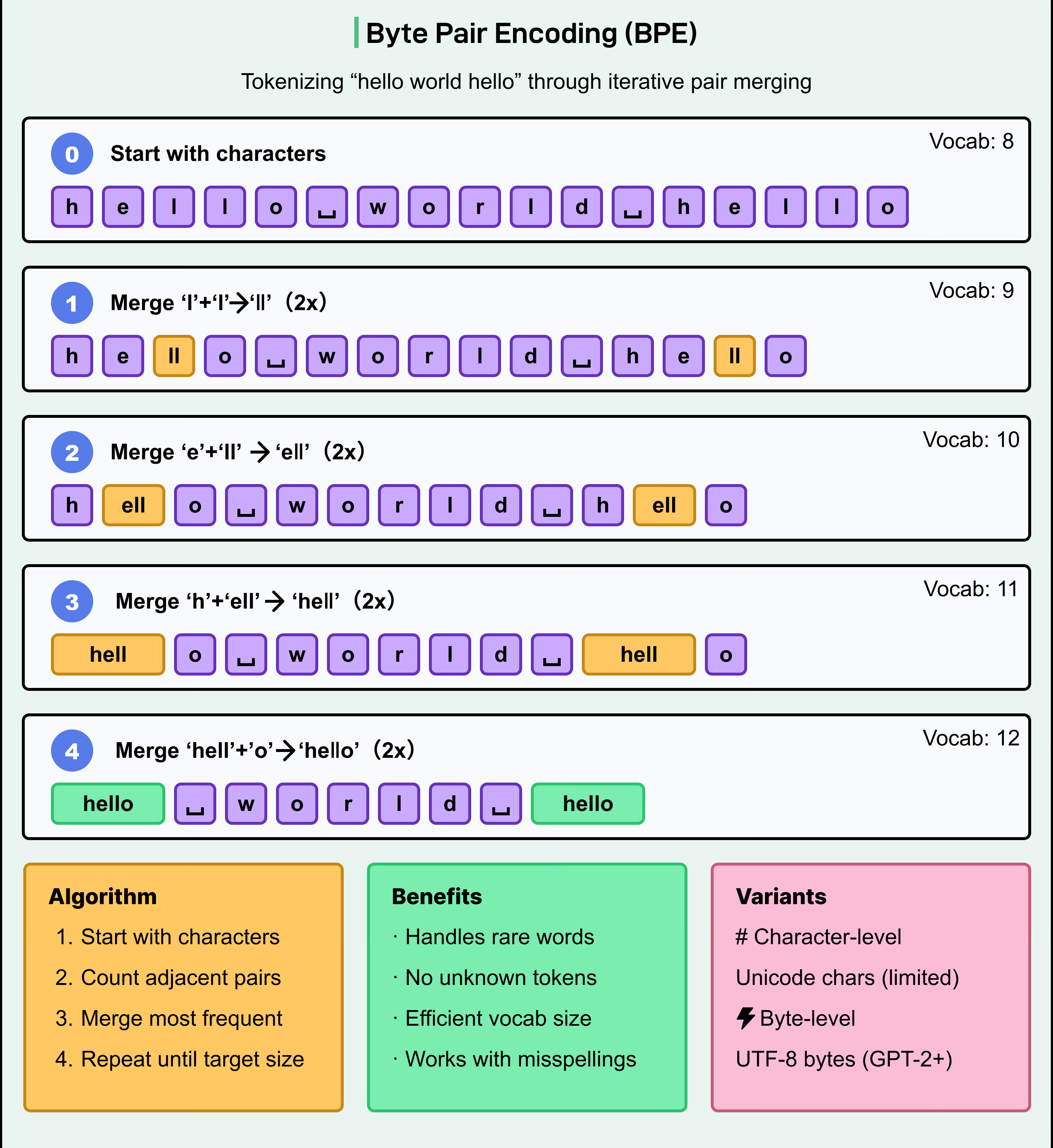
字節對編碼(Byte Pair Encoding, BPE)
BPE是現代大型語言模型(LLMs)中最常用的 tokenization 方法之一,應用於GPT-2、GPT-3、GPT-4等模型。工作原理:
從包含單個 chatacter 的基本詞彙(vocabulary)開始。
統計訓練語料(corpus)中相鄰 character pairs 的頻率。
迭代地將最常見的字符對合併為新的 token。
重複此過程,直到達到預定的詞彙(vocabulary)量大小。
")
BPE生成靈活的子詞詞彙(sub vocabulary),能高效表示常見字(word),同時也能分解罕見單詞。這有助於模型處理拼寫錯誤(misspellings)、複合詞(compound word)和未知詞,而無需依賴「未知詞元」(unknown token)。
byte-level BPE是一種重要變體,直接操作 UTF-8 bytes 而非 Unicode characters,確保任何可能的 character(即使訓練時未見過)都能被表示,從而避免「未知詞元(unknown token)」問題。
WordPiece
WordPiece 由 Google 提出,應用於 BERT、DistilBERT 和 Electra 等模型。工作原理:
與 BPE 類似,從字符級詞彙(character-level vocabulary)開始。
不同於僅基於頻率合併,WordPiece 選擇能最大化訓練數據似然值(maximize the likelihood of the training data)的字符(character)對進行配對(paring)。
使用特殊前綴(通常為
「##」)標記非單詞開頭的子詞詞元(subword tokens)。
例如,
「unhappy」可能被分詞為["un", "##happy"]。SentencePiece
SentencePiece 是 Google 開發的分詞器(tokernizer),直接處理原始文本(raw text),無需語言特定的預分詞(language-specific pre-tokenization),應用於 T5、XLNet 和 ALBERT 等模型。工作原理:
將輸入文本視為 a raw stream of Unicode characters,包括空格。
將空格作為特殊符號(通常為
「_」)保留。可採用 BPE 或 Unigram 語言模型算法。
無需語言特定的預分詞(pre-tokenization)處理。
特別適用於無明確詞邊界的語言(如日語或中文)。
例如,短語「Hello world」可能被分詞為
["_Hello", "_world"],其中「_」表示詞邊界。Unigram
Unigram 常與 SentencePiece 結合使用,採用概率方法而非基於合併的分詞方式。工作原理:
從大量可能的子詞候選詞彙開始(a large vocabulary of possible subword candidates)。
迭代地移除對訓練數據表示能力影響最小的 token。
使用概率模型尋找最可能的單詞分割方式。
與 BPE 或 WordPiece 的「自下而上」合併方式不同,Unigram像雕塑般「自上而下」修剪詞彙,保留更多分詞選項,從而在推理階段更靈活。
")

詞元與上下文窗口
大型語言模型的「上下文窗口(context window)」是其一次能處理的最大 token 數量,這個限制直接影響:
輸入長度:模型在生成回應前能考慮的文本量。
輸出長度:模型在單次生成中能輸出的內容量。
連貫性:模型在較長對話或文檔中保持主題一致性的能力。
早期模型如 GPT-2 的上下文窗口約為 1,024 個 token,GPT-3 增加到 2,048 個token。當前領先模型(如Gemini 2.5 Pro)可達 100 萬個 token 以上。
關於分詞的關鍵知識
Token 計數
了解 token 計數的重要性在於:
估算API成本:許多大型語言模型的API按 token 計費。
遵守上下文窗口限制:確保輸入和輸出不超過模型上限。
優化提示設計:減少不必要的 token 以提升效率。
對英語文本的粗略估計(具體因語言和分詞器而異):
1個詞元 ≈ 4個字符
1個詞元 ≈ 0.75個單詞
100個詞元 ≈ 75個單詞,約等於1段文字
分詞的特殊行為
分詞可能導致一些意外行為:
非英語語言:許多分詞器對非英語文本的分詞效率較低,單詞需要更多 tokens 表示。
特殊字符:不常見的字符、表情符號或特定格式可能消耗更多詞元。例如,單個表情符號「🧠」可能被拆為多個 tokens,導致語義失真或 token 數量意外增加。
數字與程式碼:某些分詞器對數字和程式碼的處理方式不符合直覺,可能將其拆分為多個 tokens,影響模型的數值推理或程式碼生成能力。
Tokenization 如何影響大型語言模型的性能
許多大型語言模型的挑戰和特殊行為並非來自模型本身,而是來自 Tokenization 分詞方法。以下是分詞對不同性能方面的影響:
拼寫與錯字:
當用戶拼錯單詞時,分詞器常將其拆為不熟悉或罕見的 token 組合。由於模型依賴常見 token 序列的模式,陌生 token 會干擾其理解或糾正輸入的能力。跨語言性能:
為英語設計的分詞器對其他語言(特別是不同字體或形態的語言)通常拆分出更多詞元。這導致更高的 token 數量、更差的上下文壓縮,以及非英語文本的流暢度和準確度下降。數值與數學推理:
數字常被拆為多個 tokens(例如「123.45」可能變為["123", ".", "45"])。這破壞了數值的整體性,影響模型的數學運算能力,因為模型看到的不是完整的數字,而是分段的符號。程式碼生成與理解:
程式語言依賴精確的語法和結構。若分詞器對運算符、標識符或縮進的拆分不一致,可能影響模型生成或解析程式碼的準確性。良好的程式碼分詞能提升模型在程式碼補全、格式化及錯誤檢測方面的表現。
尷尬的「3.11 vs 3.9」問題
大型語言模型常在簡單的數值比較(如「3.11和3.9哪個更大?」)上失敗,分詞為此提供了洞察。
以數字 3.11 和 3.9 為例,分詞器可能將其拆分為:
「3.11」→ ["3", ".", "11"]「3.9」→ ["3", ".", "9"]
對模型而言,這些不是浮點數,而是符號片段。模型並非以數值方式比較 3.11 和 3.9,而是基於訓練數據中 token 序列的統計概率進行模式匹配。
模型可能通過以下方式正確回答:
隨機性:由於模型的非確定性,有時答案正確,有時錯誤。
特定訓練:透過監督微調(Supervised Fine-Tune, SFT)或系統提示,針對常見測試問題硬編碼正確答案。
外部工具:當前模型常結合數學、數據分析或網頁搜索工具,幫助正確比較數字。
提示框架:提示中若包含量化推理的暗示,可能比通用提示表現更好。