

ChatGPT增加長期記憶功能
Meta 推出 Llama 4,支援 1000 萬 token 的上下文視窗;Google 也大幅更新 Gemini 工具。不過在這波 AI 競賽,OpenAI 的記憶功能升級最能帶來實際價值。
4 月10日,OpenAI 宣布 ChatGPT 即刻起能夠跨對話記住用戶的偏好、語氣和目標,即使在新的聊天中也能保留這些資訊。這項升級使 ChatGPT 能夠提供更連貫且個人化的回應,並在多輪對話中保持上下文的連續性。
在人工智慧代理(AI Agent)的運作中,記憶模式扮演著至關重要的角色,通常可區分為兩種類型。其一是短期記憶,亦稱為工作記憶。例如,在提示工程(Prompt Engineering)中,透過上下文學習(In-context learning)引入的資訊即是短期記憶的應用。
其二是長期記憶,這類似於人類終其一生近乎無限的資訊儲存能力。檢索增強生成(Retrieval Augmented Generation, RAG)中使用的向量資料庫檢索便是長期記憶的一個典型範例,它為 AI Agent 提供了一個近乎無限的知識儲存空間。當 AI Agent 需要特定資料時,透過檢索機制,相關資料會被提取並載入,以供後續的應用與處理。
記憶的運作方式
ChatGPT 的記憶功能主要透過兩種方式運作:
使用者主動儲存:用戶可以明確要求 ChatGPT 記住特定資訊,例如「請記住我正在學習法語」。
自動記憶:ChatGPT 會根據對話內容自動提取關鍵資訊,例如用戶的興趣或偏好,並在未來的對話中加以應用。
這種記憶機制涵蓋文字、語音和圖像輸入,使 ChatGPT 能夠在各種互動中提供一致且相關的回應。
用戶控制與隱私保護
OpenAI 強調用戶對記憶功能的完全控制。用戶可以:
在設定中啟用或停用記憶功能。
查看、編輯或刪除特定的記憶項目。
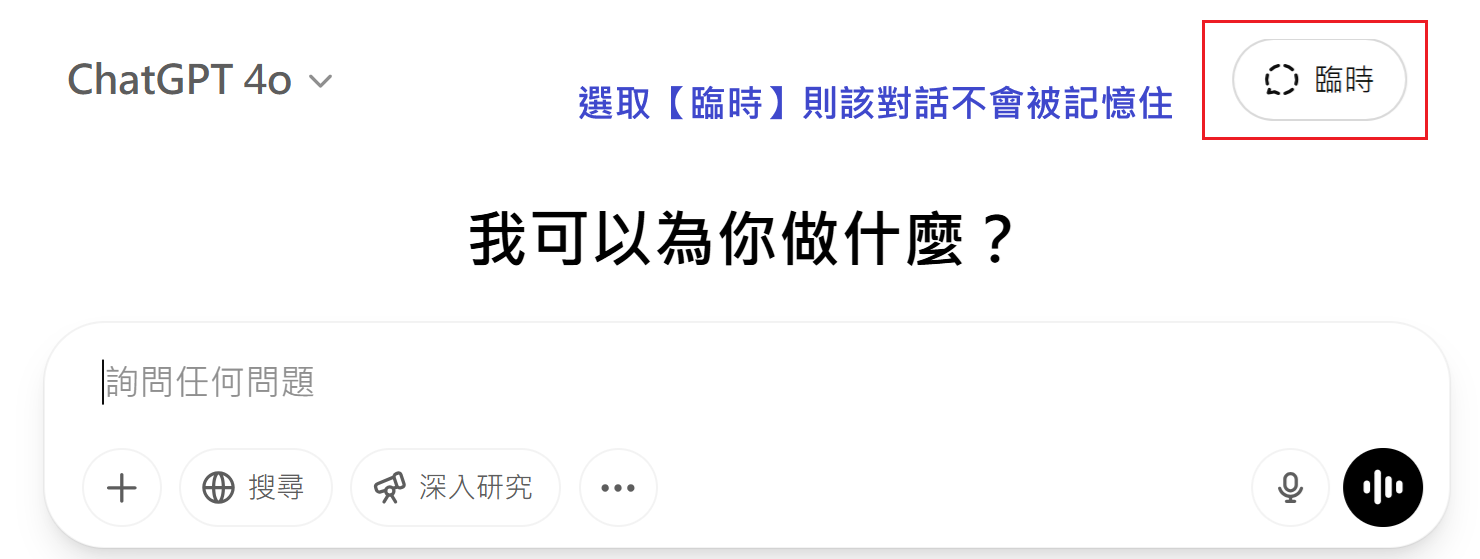
使用「臨時聊天」功能,進行不會被記錄的對話。
這些措施有助於保護用戶的隱私,並防止 AI 記住不必要或敏感的資訊。
目前,這項記憶功能已經向全球的 ChatGPT Plus(每月 $20)和 Pro(每月 $200)用戶推出,預計將在未來幾週內擴展至企業、團隊和教育版用戶。
技術與未來展望
這項記憶升級可能採用了檢索增強生成(RAG)等技術,允許 ChatGPT 在生成回應前引用外部知識庫,從而提升回應的相關性和準確性。這種能力使 ChatGPT 能夠在教育、創作、個人助理等領域提供更具針對性的支援。
