

世界前十大獨角獸最新排行
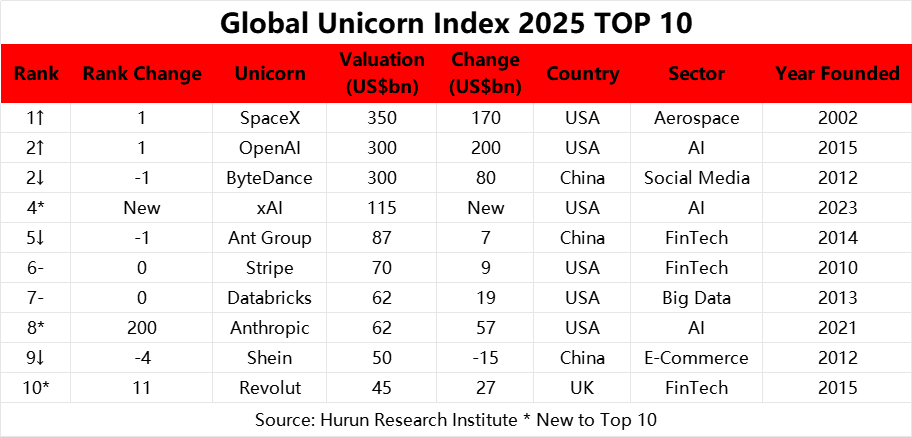
整體趨勢重點
AI 領域崛起:
OpenAI($300B)、xAI($115B)、Anthropic($62B)三家AI企業擠進前十,其中xAI與Anthropic為新進榜(*New),反映生成式AI與AGI的投資熱潮持續升溫。
美國主導:
前十名中有七家企業來自美國,且前三名皆為美國公司,顯示其在創新創業、生態資源與資本市場的優勢依舊明顯。
中國企業下滑:
Tiktok 母公司 ByteDance 雖仍居第三,但排名下滑,成長幅度遠低於OpenAI與SpaceX。
Shein 估值下降15%,跌出前五。目前已經選定香港上市。
螞蟻金服雖仍在榜,但增幅僅 $7B。在 AI 強勢崛起的年代,其排行將持續下探
新進榜者實力強勁:
xAI 以一年創業時間躍居第四,Anthropic 則從200名外暴衝至第八,皆顯示生成式AI在估值與資本關注上的爆發力。
名單中較不為人熟知的投資標的是 Databricks,卻是 AI 時代最關鍵的公司之一。相比已上市的 Snowflake 與 Palantir,Databricks 長年被視為矽谷最具潛力的 IPO 候選之一,但至今仍選擇透過初級市場募資,不僅持續打磨產品,也長年維持全矽谷員工薪資中位數最高的紀錄(今年可能會輸給 LLM 公司,如 OpenAI、Anthropic)。
事實上,許多日常應用程式的背後,都仰賴 Databricks 的 Data Lake 技術以支撐龐大的運算需求。我們透過 SPV 投資 Databricks,對其技術與發展有深刻了解。若要完整說明資料科學與資料工程的演進,足以分成十集細說從頭;但今天我盡量簡要回顧其創立歷程,並介紹其關鍵技術 Data Lake 及現今業界積極投入的 Data Lakehouse,以理解其在大數據與 AI 時代的重要地位。
至於技術的演進,如何從OLAP到Hadoop/MapReduce到Spark,有機會再細談。不喜資料工程技術的讀者,可直接跳到文章後段。
一切的起點:Databricks 的創立故事
Netflix 百萬獎金競賽
2006 年,Netflix 發起一場名為「Netflix Prize」的競賽,只要能將推薦演算法的效能提升 10%,即可獲得 100 萬美元獎金。
當時,網際網路帶來大量非結構化與結構化數據,企業急於尋找分析這些資料的最佳解法。而實現這一點,需要龐大的儲存與運算能力。
當時最主流的工具是 Hadoop,於 2006 年問世,但效率低落且難以操作,無法勝任真正的大數據需求。
Spark 的誕生
到了 2009 年,競賽吸引了超過 5 萬名參與者,卻仍無人達標。資料集規模極大,包含 18000 部電影、超過 1 億筆評分、45 萬名用戶資料。
Berkeley 博士生 Lester Mackey 也決定參戰,但馬上面臨現實困難——沒有工具能有效處理如此龐大的資料。
他的同學 Matei Zaharia 開發了一套更高效的運算框架,這個工具正是 Spark 的前身。
儘管他們成功提升推薦準確率達標,但因為延遲 20 分鐘繳交作品,最終由 AT&T 的團隊獲勝。
Spark 的崛起與 Databricks 的創立
Zaharia 早在 Yahoo 工作時就發現 Hadoop 的不足,決定與 Berkeley AMPLab 團隊攜手創建 Spark,並將其商業化,Databricks 應運而生。
Databricks 的初始願景,就是打造一個統一的平台,讓數據分析與 AI 建構變得簡單易行。
實驗室→明星開源項目→成立公司專責管理Spark 持續發展

在柏克萊大學,AMPLab(Algorithms, Machines, and People Laboratory)堪稱是開源與數據計算技術的創新搖籃。這個跨領域實驗室不僅孕育出眾多劃時代的開源專案,也成為創業精神與工程實踐結合的典範。2007 年至 2011 年間,來自 Stanford 創業團隊獲得的天使與風投案數為 203 筆,居全美之冠;而 UC Berkeley 緊隨其後,以 90 筆名列全美第三,顯示 Berkeley 雖未強調創業文化,但學生在創業能力與熱情方面同樣不容小覷。
更值得注意的是,許多當今主流的大數據與雲端運算框架——包括 Spark、Shark、Alluxio(前稱 Tachyon)、Mesos 等,皆發源於 AMPLab。這些專案如今已成為全球數據處理與 AI 基礎架構不可或缺的一部分。

Spark:從學術實驗室到全球運算平台的崛起
Apache Spark 的誕生可追溯至 2009 年,最初只是 AMPLab 內部的研究性專案,由博士生 Matei Zaharia 領銜開發。Spark 的核心設計——RDD(Resilient Distributed Dataset),為分散式資料處理帶來突破性的彈性與效率,讓記憶體內運算成為可能。
2013 年,Spark 正式加入 Apache 基金會,同年 Zaharia 與 AMPLab 團隊聯合創辦了 Databricks,將 Spark 商業化並帶向全球市場。與許多為商業導向而設計的框架不同,Spark 從一開始就烙印著學術深度與理論創新。其 SQL 智能查詢、流處理(Streaming)、機器學習(MLlib)、圖形計算(GraphX)等模組,幾乎都可在學術論文中找到對應的演算法與設計思想,展現了學術研究如何直通實際應用。
Spark 最關鍵的創新,在於統一了異質的資料處理模型——MapReduce、SQL 查詢、即時流處理、機器學習、圖分析——並將它們整合於單一平台與一致的 API 之中。這種一體化設計大幅降低了數據團隊的學習與維運成本,也讓 Spark 成為從資料工程到 AI 建模的理想選擇。
開源生態與全球社群的壯大
Spark 的迅速壯大,離不開其開源社群的活躍與貢獻。自從 2013 年加入 Apache 基金會以來,Spark 專案的月活貢獻者數量呈爆炸性成長,參與貢獻的公司也從最初的 17 家擴展至超過 50 家,其中包括阿里巴巴、百度、騰訊、搜狐與網易等多家中國科技公司,顯示其國際化程度與企業落地能力。

除了技術貢獻之外,Spark 的社群活動也遍及全球——從每年盛大的 Spark Summit(後來更名為 Data + AI Summit),到遍佈各地的社區 Meetup 活動。上圖所示的全球 Meetup 分布圖中,那些遍布世界各地的紅點仍在不斷增加,反映出 Spark 的技術生命力與實用價值。

關鍵人物:Matei Zaharia 與學術產業雙棲的傳奇
Databricks 聯合創辦人、現任 CTO Matei Zaharia 無疑是 Spark 背後的靈魂人物。他於 2012 年自 AMPLab 博士畢業,現亦擔任 MIT 助理教授。Zaharia 的研究觸角遍及多項前沿系統專案,包括 Spark、Shark、Hadoop 改進、Mesos、資源公平調度(Multi-Resource Fairness)、MapReduce 排程優化、基因序列對齊器 SNAP 等。

為什麼 Spark 和 Databricks 有其存在必要?
Spark 的必要性:
大數據愈來愈龐大,處理愈來愈困難。要提取價值,必須有像 Spark 這樣的運算框架。這就是「追風」一:大數據浪潮。Databricks 的必要性:
雲端運算改變了一切——讓儲存與運算資源可以無限擴展,但開源軟體管理依然複雜。Databricks 的價值就是結合 Spark 的威力與雲端服務的易用性。這是「追風」二:雲端轉型。
Databricks 曾拒絕一家金融機構提出的 2000 萬美元 on-premise 授權提案,當時公司年營收僅 1000 萬美元。
Spark 相對 Hadoop 的技術優勢
Databricks 簡單來說,就是讓複雜的事變得可行、讓簡單的事變得輕鬆。
Spark 架構中,Driver 負責分派任務,Cluster Manager 分配資源,Executors 執行任務。相較於 Hadoop,Spark 更快、更具成本效率。
由於機器學習極度依賴計算力,Databricks 初期的客戶以大型企業的資料科學家與 ML 工程師為主。這與 Snowflake 專注商業分析的方向形成對比。
Spark 是一種運算框架,不是資料庫,它坐落在如 S3 的物件儲存之上,處理的是結構化與半結構化數據。與 Snowflake 作為結構化數據倉的定位完全不同。
從開源走向商業化
2013~2015 年間,Databricks 持續打磨產品,尋找產品市場契合點。
2016 年,Ali Ghodsi 出任執行長,公司管理層大幅改組,引入具企業級銷售經驗的團隊。技術創辦人仍然留在公司,專注技術創新。
為了創造商業價值,Databricks 開始保留部分 Spark 功能作為專屬技術,不再全數開源。這是艱難但必要的轉型。
這也是「追風」三:開源技術的商業化浪潮。
走向主流:從 Spark 到平台型企業
Databricks 採取雲端代管 Spark,從運算收費中抽取高毛利差價,主攻大型企業與資料密集的新創公司。
2017 年,Databricks 與 Microsoft Azure 合作,推出 Azure Databricks,實現技術整合與聯合銷售。這一策略成功借力微軟通路,擴展客戶群。
此舉甚至可視為日後 Microsoft 投資 OpenAI 的前哨戰。
成為數據平台與「Lakehouse」推手
2018~2021 年,Databricks 共募得五輪資金,估值從 5 億美元一路攀升至 280 億美元:
2018:D 輪 1.4 億
2019:E 輪 2.5 億、F 輪 4 億
2021:G 輪 10 億、H 輪 16 億(估值 280 億)
期間推出兩項關鍵開源專案:
Delta Lake:讓 Data Lake 可追蹤與治理
MLflow:開放式機器學習開發框架
這奠定了 Databricks 主打的「Lakehouse」理念:結合資料倉(Data Warehouse)的即席查詢能力與資料湖(Data Lake)的規模與成本優勢。
Databricks 的現在:AI 時代的資料作業系統
2022 年起,Databricks 加速產品整合與併購,從資料擷取、轉換、運算、SQL 查詢到 AI 建模與治理,建立完整的 Data & AI 平台。
其核心定位明確:成為企業資料的統一作業層,幫助企業更快、更有效率地從資料中獲取洞見。
目前的主要功能模組包含:
資料科學:以 Spark 為基礎的程式化分析
資料倉儲:儲存與查詢結構化資料
資料工程:建置 ETL 流程與編排
AI 建模:MLflow、生特徵庫、模型服務與精調
智慧代理:Agent framework、向量資料庫等
安全治理:資料資產盤點與權限控管
Databricks 的最終願景:用戶可以向資料代理人提問,獲得未來預測,而不只是回顧過去。

從Data Lake 到 Data Lakehouse
當我們討論 Data Lake(資料湖) 與 Data Warehouse(資料倉儲) 的異同與技術演進時,實際上是在談論 企業資料架構如何因應資料規模、種類與用途變化 的演化過程。以下將從定義、架構、技術演進、代表廠商與使用情境來全面比較與剖析。
一、基本定義與比較總覽
二、歷史演進與技術脈絡
1. 資料倉儲的起源與發展(1990s–2010s)
1990 年代由 Bill Inmon 與 Ralph Kimball 發展出企業資料倉儲理論與建模(如 Star Schema、ETL 流程)。
初期主要使用商用關聯式資料庫(如 Oracle、Teradata、IBM DB2)。
採用 OLAP(Online Analytical Processing) 模式,針對 KPI 與商業報表最佳化。
技術關鍵詞:ETL (Extract, Transform, Load)、Dimensional Modeling、Batch Processing
關鍵廠商:
Teradata(資料倉儲先驅)
Oracle(ERP 結合 DW)
IBM Netezza、SAP BW
Microsoft SQL Server + SSIS/SSAS/SSRS
2. Big Data 與資料湖的誕生(2010s)
資料來源爆炸性成長(社群媒體、IoT、影像、sensor),資料型態趨於多樣化。
Hadoop 出現(2006–2012)掀起分散式檔案儲存熱潮。
Schema-on-Read 成為主流,允許資料以原始形式儲存至 HDFS、S3 等平台中,分析時再套用結構。
重點從「資料整齊」轉向「儲存全量、保持彈性」。
關鍵技術:
HDFS(Hadoop Distributed File System)
MapReduce、Hive、Pig、HBase
Spark(解決 MapReduce 效能瓶頸)
Parquet、ORC(列式儲存格式)
關鍵廠商:
Cloudera / Hortonworks / MapR(Hadoop發行版)
Amazon S3 + Athena
Azure Data Lake / Google Cloud Storage
Databricks(Apache Spark 商業化)
3. 資料湖與資料倉儲的融合:Data Lakehouse(2020s)
大量企業將資料湖導入後,發現:
雖可儲存所有資料,但分析效率不高,缺乏一致性管理與治理機制。
為解決此問題,Data Lakehouse 概念誕生:整合 Data Lake 的彈性與 Data Warehouse 的治理與效率。
代表產品如:
Databricks Delta Lake
Snowflake on S3
Google BigLake
Apache Iceberg / Apache Hudi
技術特徵:
ACID transaction on object storage
Metadata Layer(如 Delta Table, Iceberg Table)
Time travel、schema evolution 支援
整合 BI、ML、AI 工作流程
三、使用情境差異
四、未來趨勢
Lakehouse 成主流架構:Databricks 和 Snowflake 均在強化 Lakehouse 功能。
Open Table Format 標準化:如 Delta Lake、Apache Iceberg、Apache Hudi 成為兼容 Spark、Trino、Flink 等工具的中介層。
資料治理與安全提升:Unity Catalog、Data Lineage、Fine-Grained Access Control 成為企業資料湖治理關鍵。
AI 原生整合:資料湖將成為 AI 模型訓練的資料主幹,支援向量資料庫(Vector DB)、RAG 等應用。
Databricks 與 Snowflake

Databricks 與 Snowflake 作為現代數據平台的兩大巨頭,正展開一場激烈的競爭,爭奪企業「資料 + AI」轉型過程中的關鍵地位。雖然兩家公司都從「處理大規模資料」起家,但技術出發點、平台策略與市場重心存在明顯差異,並逐漸向彼此靠攏,形成典型的 橫向融合競爭(converging competition)。
核心定位差異:AI 原生 vs BI 原生
➡ Databricks 為 AI 原生平台,Snowflake 則為 BI 原生平台
AI 戰略:Databricks 領先,Snowflake 加速追趕
✅ Databricks 的 AI 優勢:
買下 MosaicML:提供企業訓練自家 LLM 的完整堆疊(模型 + 訓練 +推論)
推出開源 LLM DBRX:強化其 AI 軟體技術形象
原生整合 RAG、向量搜尋、Agent Workflow 編排
提供 MLflow、Feature Store、模型部署 API,企業可全流程管理 AI 專案
⚠️ Snowflake 的 AI 進展:
收購 Neeva(RAG 搜尋引擎)、Applica AI(文件理解)、Streamlit(建前端 UI)
推出 Snowflake Cortex:提供即時 AI 推論 API(OpenAI + 自家模型)
發展 Snowpark ML:讓資料科學家在 Snowflake 上做模型訓練與部署
引入 向量索引(Vector Indexing) 與外部模型串接(如 Bedrock)
➡ Databricks 優勢在「AI 原生整合」與開源訓練能力,Snowflake 則以即時推論與 SaaS 化簡便為主
客戶導向與商業策略
技術架構對比:Lakehouse vs Cloud Warehouse
🔷 Databricks:Lakehouse 架構
支援結構化 + 非結構化資料(圖像、PDF、影片)
資料與 AI 原生整合(如支援向量資料、模型推論、微調)
提供 Delta Lake 強化 ACID、時間旅行、版本控制
Unity Catalog 為多雲統一治理基礎
🔶 Snowflake:Cloud DW + 外掛 AI 模組
資料集中於 SQL 表格(結構化為主)
非結構化資料支援近年逐步加強,但仍須轉換至內部格式
AI 模型整合偏向黑箱 SaaS API(非原生訓練)
專注於 SQL 開發者與分析師生態
Databricks如何在AI競賽中搶佔先機
事實上,Databricks 早已成為AI策略中不可或缺的一環。如今,每年營收以約 60% 的速度年增,預計到2025年底,年度化營收(ARR)將超過50億美元。
Databricks 最新 ARR、估值與客戶規模
雖為未上市公司,Databricks 已展現極高成長力道:
2024 年底 ARR 已達 ≈ 3 B USD,年增約 60 %(2023 年為 1.9 B)。
2025 年 7 月預估可達 3.7 B USD ARR,YoY增長 50 %。
Databricks SQL(倉儲類子產品)也預計年底達 1 B USD ARR;目前為 400–600 M ARR。
客戶總數超過 15,000 家,其中 >500 家的貢獻超過 $1M ARR,且有近 50 家大客戶年付 $10M+。
最新估值約為 62 0億美元。

AI 市場的關鍵先機
隨著企業紛紛導入生成式AI及類 ChatGPT 的應用,如何利用既有資料來訓練大型語言模型(LLM)成為當務之急。然而,在此之前,企業需先整理資料,使其乾淨且可靠。Databricks推出 Mosaic AI 和其自家 LLM(DBRX),能協助企業將內部專有資料整合、定制這些模型,真正發揮「資料智慧」(data intelligence)價值。
Databricks 的競爭強勢到底從何而來?
Lakehouse架構: 同時支援結構化和非結構化資料,一站式滿足BI與AI開發。
資料智慧 (Data Intelligence):整合資料整理、治理、LLM 客製化和向量搜尋,是企業AI應用的核心基建。
策略性併購:如併購 MosaicML、Tabular、Neon 等,提高製模、治理與即時處理能力。
資金實力雄厚:2024年12月募資達 100億美元,加上逾 5.25億美元債務,短期不急上市。
夥伴生態拓展:與 Microsoft、Google Cloud、Meta、Anthropic、SAP 等策略聯盟,有助提升產品能見度與採用率。
營收與客戶規模比較總表
成長速度:Databricks 勝出(50–60 % vs Snowflake 的 24–26 %)。
客戶規模:Databricks 客戶更多,但兩者高價值客戶都十分強勁。
營收規模:Snowflake 略高,但差距在縮小中。
小結與展望
Databricks 已從資料工程供應者,成功轉型為AI基礎建設平台,透過 lakehouse、資料治理與AI整合,站上企業級 AI 應用的浪頭。目前看來,Databricks 在生成式 AI 與資料整合方面仍保有領先優勢。
2012年,Facebook 約以 1,040 億美元成為美國最大 IPO 市值之一,我們預估 Databricks有機會打破這個紀錄,雖然每年華爾街都把 Databricks 列為最可能上市公司之一,但預估 2026 年上市機率極高。