

1945 年,在新墨西哥州洛斯阿拉莫斯實驗室的某個角落,烏拉姆(Stanislaw Ulam)盯著一副撲克牌發呆。他養病期間沒有太多事可做,卻有一個問題纏住他不放:中子在鈾核裡的擴散行為太複雜,沒有解析公式可以直接求解。
他想到的解法,後來改變了整個科學計算的面貌。
與其試圖推導出公式,不如大量地去試。讓電腦模擬數以萬計的隨機路徑,統計有多少次達到目標,再從比例推算出機率。他把這個想法告訴了馮諾依曼(John von Neumann),兩人給它取了一個帶著賭城氣息的名字:蒙地卡羅模擬。
名字來自烏拉姆那個愛在摩納哥揮霍的叔叔。但這個方法本身,不浪漫,它是嚴謹的,也是深刻的——它把「解析的困難」翻譯成「計算的重複」,把人解不開的方程式,交給電腦去用蠻力逼近。
這個時刻,是現代財務數學真正的起點之一。而它的地基,是一個極為弔詭的東西:一台製造假象的骰子。

在蒙地卡羅方法提出之前,「模擬」會用來測試一個已經被完全了解的問題,而「抽樣」會用來衡量模擬中的不確定性。而蒙地卡羅方法反轉了這種模式,使用一個機率類比來解決決定性問題。
Before the Monte Carlo method was developed, simulations tested a previously understood deterministic problem and statistical sampling was used to estimate uncertainties in the simulations. Monte Carlo simulations invert this approach, solving deterministic problems using a probabilistic analog. — wiki
一、人工骰子
蒙地卡羅的核心,是大量的隨機數。
但電腦要如何生成「隨機」?電腦是確定性的機器,每一步運算都遵循明確的指令,不允許任何「說不準」。你不能讓一台機器真正地擲骰子。
解決方案是偽隨機。
工程師們設計出一套數學公式,從一個起始值(稱為「種子」)出發,每一步按照確定的公式推算出下一個數,生成一串看起來毫無規律的數字序列。這串序列,統計上通過所有你能想到的隨機性檢驗——均勻分佈、互相獨立、沒有週期——但它本質上,是一張已經寫好的劇本。給定相同的種子,整條序列完全可重現。
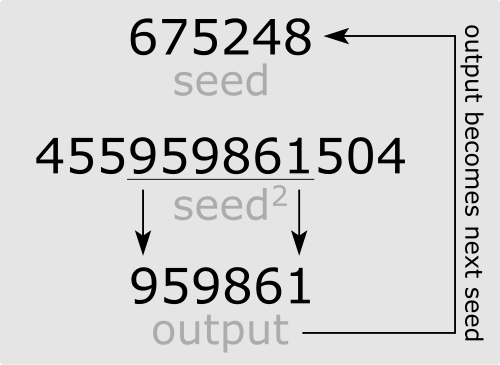
現代最廣泛使用的偽隨機算法,叫做 Mersenne Twister(MT19937),由日本學者松本眞與西村拓士在 1997 年發明。它的名字來自它的週期長度,恰好是一個梅森質數:2¹⁹⁹³⁷ − 1,一個長到難以想像的循環——在這個週期結束之前,序列絕對不會重複。它維護一個由 624 個整數組成的內部狀態陣列,每次呼叫 random() 時,從這個狀態推導出下一個數字,狀態也跟著演進。
你在 Python 裡呼叫的 random.random(),你在 R 裡執行的 runif(),你的選擇權定價程式在背後跑的那一百萬條路徑——它們幾乎全部建立在這台人工骰子上。它不是真正的隨機;它是一個精心設計的確定性算法,偽裝成隨機。給定相同的種子,整條序列完全可重現,一個數字都不差。
這並非缺陷,而是特性。科學需要可重現性,模擬需要能被驗證,調試需要能重跑。偽隨機的確定性,恰好是工程師最需要的那種「受控的不確定性」。
但這裡有一個重要的警示,比大多數使用者意識到的更重要:Mersenne Twister 適合模擬、統計抽樣、遊戲這類場合,但它絕對不適合密碼學或任何需要安全隨機性的場合。原因是,只要觀察到連續 624 個輸出值,就可以完全重建它的內部狀態,預測所有後續的亂數。這台骰子,可以被破解。需要真正不可預測的隨機,必須改用依賴作業系統熵源的方案——Python 的 secrets 模組,或 SystemRandom——它們從硬體雜訊、網路封包時間差等真實物理過程取樣,才能稱得上是真正意義上的隨機。
但在財務數學的場景裡,偽隨機的「可重現性」反而是一個工程優勢。問題不在這台骰子夠不夠安全,而在於:這個骰子,能夠代表那個真實世界嗎?
二、從骰子到常態分佈,再到選擇權
讓我們沿著這條邏輯鏈走下去。
電腦有了人工骰子,可以模擬均勻分佈的隨機數。從均勻分佈出發,用 Box-Muller 方法或類似的轉換,可以生成常態分佈的隨機數。從常態分佈,可以模擬布朗運動——那個在每一個無窮小時間步驟裡,都往某個隨機方向走一小步的連續隨機過程。
布朗運動,是整棟財務數學大廈的鋼骨。
它的名字來自植物學家羅伯特·布朗,他在 1827 年觀察到花粉粒在水中的不規則抖動,完全無法預測下一刻飄向何方。愛因斯坦後來給出數學解釋:這是無數水分子對花粉粒碰撞的集體效應,每次碰撞都是獨立的、方向隨機的,疊加之後,形成了那條到處拐折、沒有任何一點有切線可言的連續曲線。

金融學家把股價的變動建模為一種帶有漂移項的幾何布朗運動:
dS = μS dt + σS dW
S 是股價,μ 是期望收益率,σ 是波動率,dW 是布朗運動的微小增量。這條公式背後,是一個重要的統計事實:在這個假設下,股價的對數收益率服從常態分佈。
常態分佈,是整個現代統計推斷的核心。它之所以無處不在,根源是中央極限定理——大量獨立的隨機變數相加,無論原始分佈長什麼樣子,只要樣本數夠大,總和的分佈就會收斂到常態分佈。藥物試驗裡的療效估算是它,工廠品質管制裡的允許誤差是它,選舉民調裡的抽樣誤差也是它。
而讓它能被計算、被模擬、被大規模應用的,正是那台人工骰子。
這環環相扣:人工骰子生成均勻分佈,均勻分佈轉換成常態分佈,常態分佈模擬布朗運動,布朗運動描述股價,股價的運動讓選擇權可以定價。整個鏈條,從最底層那個確定性的偽隨機算法,一路往上,建起了現代金融工程的全部定價架構。
電腦算力的每一次飛躍,都讓這棟大廈又往上蓋了幾層。沒有個人電腦的普及,蒙地卡羅是實驗室的工具;有了它,它變成了每一家銀行交易室的基礎設施。沒有高速計算,隨機波動率模型無法即時定價;有了它,市場上的衍生品交易每秒鐘都在算數十億次。
隨機,是地基。電腦算力,是讓這個地基得以支撐整棟摩天樓的鋼筋。
三、Itô 引理與那個多出來的一項
在這棟大廈最關鍵的一層,住著一條看起來奇怪的數學定理:Itô 引理。
普通微積分的鏈鎖法則告訴你:如果 y 是 x 的函數,x 又隨時間變動,那麼 y 隨時間的變動率,等於 y 對 x 的導數乘以 x 的變動率。這是高中數學加上一點大學微積分的範圍,不複雜。
但在布朗運動的世界裡,這條公式必須多加一項。
原因是布朗運動的波動太劇烈——它的「二次變差」不為零。在普通的可微函數裡,高階的微小項最終可以被忽略;但布朗運動的路徑處處不可微,那些高階項貢獻了有限的量,不能扔掉。Itô 引理,就是把這個額外的一項精確地寫出來的定理。

這個多出來的一項,是 Black-Scholes 方程式能被推導出來的關鍵。
一九七三年,布萊克(Fischer Black)與舒爾斯(Myron Scholes),以及默頓(Robert Merton)獨立地用這套數學機器,推導出了選擇權的公平定價公式。它的深層邏輯是:若你持有一個選擇權,同時反向持有一定比例的標的股票,就可以構成一個瞬間消除隨機性的「動態避險組合」。這個組合的報酬必須等於無風險利率,否則就出現了套利機會。從這個無套利條件出發,加上 Itô 引理,就推導出了那條封閉的定價公式。

這是財務數學最輝煌的時刻之一。不確定性,被折疊成了一個參數——波動率 σ。風險,有了精確的價格。「風險中性定價」的框架說:在一個可以動態避險的完備市場裡,任何衍生品的價格,等於在「風險中性測度」下,它未來報酬的期望值再折現。
隨機,讓不確定性可以交易了。
 - Meaning, Formula, Example")
四、那些被折疊進去的假設
但在慶祝這個輝煌之前,必須停下來問一個問題:這棟大廈,建在什麼地基上?
Black-Scholes 成立,需要一系列假設:股價服從幾何布朗運動;市場是連續的;可以無摩擦地動態避險;波動率是恆定的。每一個假設,都是在說:「在以下這些條件控制的情況下……」
問題在於,這些條件往往沒有被清楚地寫在使用說明上。
使用者看到的是一個漂亮的公式,輸入幾個參數,吐出一個定價。公式背後那一串假設,靜悄悄地被折疊進去,成為隱形的條件。市場在正常運轉的時候,這些假設大致成立,公式給出的答案也大致合理。於是信心逐漸累積,假設的存在被遺忘,工具本身被當成了真理。
這是一個精細的認識論陷阱,而且它非常難以察覺,因為它在大多數時候都不會出發警報。
常態分佈的尾部,太薄了。
真實金融市場發生的極端事件,其頻率遠比常態分佈預測的高得多。1987 年的「黑色星期一」,道瓊斯指數單日崩跌超過 22 個百分比——若股價真的服從常態分佈,這個事件發生的機率,是幾乎不可能以常態標準差來衡量的天文數字。2008 年的金融海嘯,2020 年的疫情衝擊,一次次地重演著同樣的故事:模型說這不該發生,現實說它就是發生了。
這就是統計學上的「厚尾」——現實世界的分佈,比常態分佈的尾部更肥,極端事件比模型預測的更常出現。
塔雷伯(Nassim Nicholas Taleb)把這類「在標準模型框架裡概率極低、卻在現實裡真實出現的極端事件」稱為黑天鵝1。他的批判,不只是針對某個具體的模型,而是針對整個「用常態分佈描述人類社會複雜現象」的思維習慣。
他說的,其實不難理解:當你把一個複雜的隨機現象,壓縮成布朗運動、壓縮成常態分佈,你是在說:「在大量獨立樣本的假設下,在各種條件控制的情況下,這個系統的行為會收斂到這個分佈。」但那些「假設」和「條件控制」,在真實市場裡從來不是免費的——它們是被你默默吞進去的代價,等到市場不再符合這些假設,帳單才會送來。
而你往往不知道帳單什麼時候會來,因為你早就忘了當初欠下了這筆帳。
五、環環相扣的鏈條,以及它斷掉的地方
讓我們把整條鏈條重新看一遍。
人工骰子(偽隨機算法)→ 常態分佈樣本 → 布朗運動模擬 → 幾何布朗運動假設 → Black-Scholes 定價 → 選擇權市場的每日交易。
這個鏈條的美麗之處,在於它的嚴密——每一個環節都有嚴格的數學支撐,從 Itô 引理到無套利原則,每一步都經得起推敲。這也是它的危險之處:鏈條的嚴密,讓人容易誤以為整個系統是穩固的;但任何一個環節的假設失效,整條鏈條都可能在看起來最不可能的時刻斷裂。
最關鍵的斷裂點,通常不在鏈條的中間,而在最底部。
當市場不再是「大量獨立參與者各自決策」的系統,而是變成所有人都在盯著同一個指標、讀同一份研究報告、用同樣的模型風控,「樣本獨立」這個假設就悄悄消失了。沒有了獨立性,中央極限定理的收斂保證就鬆動了,常態分佈的尾部估算就失效了,整棟建立在此之上的定價大廈,就站在了它不知道已經變成流沙的地基上。
更麻煩的是,越來越多的人使用相同的模型,模型本身就開始影響市場的行為,改變了它原本試圖描述的那個現實。這是一種自我指涉的迴圈:你用模型描述市場,市場因為人們相信模型而改變,改變後的市場不再符合模型,但沒有人注意到,因為帳單還沒到。
塔雷伯的貢獻,不只是提醒我們「黑天鵝存在」。更深的一層是:他指出,我們建構風險模型的那個認識論框架本身,就傾向於系統性地低估尾部風險,因為我們習慣用常態分佈思考,用歷史數據估參數,然後把這個估出來的分佈當成了現實。而歷史數據,往往恰好缺乏那些最罕見、影響最大的事件。
用已經發生的事去估計從未發生的事的機率,是統計學的原罪,也是所有風險模型最難逃脫的局。
六、在用「隨機」之前,先問三個問題
在整個財務數學的應用裡,有一個更根本的問題,往往比模型本身更少被認真對待:你憑什麼說這個現象可以用隨機來描述?
這不是廢話,而是一切的前提。
中央極限定理告訴我們,大量獨立的隨機變數相加,會收斂到常態分佈。但它的成立,依賴三個條件:樣本必須夠大,樣本之間必須獨立,以及這些樣本必須來自同一個母體。這三個條件,每一個都可能在現實中無聲地失守。
樣本夠大嗎? 這個問題比它看起來難。「夠大」的門檻,取決於原始分佈的形狀——越厚尾的分佈,需要越多樣本才能讓總和收斂到常態。金融市場的收益分佈本身就是厚尾的,也就是說,在它最需要大樣本才能收斂的地方,你恰好永遠沒有足夠多的歷史數據。因為市場的結構會改變,制度會改變,政策會改變,幾十年前的數據和今天的市場究竟還是不是同一個母體,本來就是一個值得懷疑的假設。
樣本真的獨立嗎? 在多數金融應用裡,這個假設是最脆弱的一個。每日的收益不是獨立的——有動能效應,有均值回歸,有季節性,有消息面的串聯反應。更根本的問題是:所有市場參與者都在讀同樣的數據、使用同樣的模型,他們的決策之間本來就高度相關。所謂「獨立的隨機樣本」,在這裡,從一開始就是個神話。
你觀察的是同一個母體嗎? 金融市場的制度環境在改變,參與者的結構在改變,算法交易的佔比在改變,市場微結構在改變。2008 年之前的波動率和之後的波動率,是同一個母體的樣本嗎?你用 30 年的股價數據估出來的 σ,是今天這個市場的波動率嗎?如果母體本身在移動,你的估計值永遠在追一個不停改變的靶。
這三個問題,在使用任何隨機模型之前,都必須被誠實地回答。
不是說這些問題有了滿意的答案,模型才能用;而是說,如果你連這些問題都沒有問過,那你用的不是模型,你用的是一個你不完全理解的黑盒子,恰好在平靜的市場裡給出了看起來合理的數字。那種合理,是一種危險的合理。
隨機,是一個強大的語言;但用這個語言描述一件事之前,必須先確認那件事確實說的是這種語言。若無法確認樣本獨立、樣本夠大、母體穩定,就不能用「隨機」輕易帶過——那個「帶過」,遲早會成為一個你不知道自己欠下的債。
七、如何帶著懷疑,依然好好使用工具
說到這裡,必須澄清一件事:這不是在說蒙地卡羅是錯的,Black-Scholes 是錯的,偽隨機是錯的。
它們都是極為精妙的工具,在它們適用的邊界之內,它們給出的答案是可靠的,可以交易的,可以被市場接受的。問題從來不是工具,而是使用工具的人,是否清楚地知道工具的適用邊界在哪裡。
蒙地卡羅能告訴你它的模型裡的風險分佈;它無法告訴你模型之外的世界,還藏著什麼它沒有想到的面孔。
正確的使用姿態,大概是這樣的:
第一,把假設寫清楚。每次使用一個定價模型,都應該能夠明確說出它依賴哪些條件——市場假設、分佈假設、獨立性假設。這些假設,不是裝飾,是模型的一部份,缺了它們,模型的輸出就沒有意義。
第二,持續問「這些假設現在成立嗎?」市場不是靜止的;假設在某段時期成立,不代表它永遠成立。當市場結構改變,當相關性突然飆升,當流動性消失,那些你習以為常的假設條件,可能正在悄悄失效,而你的模型還渾然不知地繼續吐出數字。
第三,對尾部保持敬畏。常態分佈是一個非常有用的起點,但你對真實分佈的尾部,永遠都知道得比你以為的少。在頭寸規模和風險控制上,給尾部留出比模型建議的更多的空間,是一種非常理性的謙遜。
第四,也是最根本的一點:回到第一性原理。當結果開始讓你感到困惑——價格偏離了你的模型、風控指標給出了奇怪的訊號、市場行為違反了你的直覺——這個時候不是重新校準參數的時候,而是回去問「我的底層假設,還站得住嗎?」從最基礎的邏輯重建,比在一棟地基已經鬆動的樓上繼續加蓋,要安全得多。
Pascal 和 Fermat 通信的時候,只是想解決一個賭局中途中斷的賭注分配問題。他們不知道自己在奠定什麼。那個問題要求他們精確地思考「如果賭局繼續,所有可能結果的分佈是什麼」,而一旦你開始精確地思考這件事,就踏上了一條路,那條路的盡頭,是統計推斷、是布朗運動、是 Itô 引理、是 Black-Scholes,是現代金融市場每天流動的數兆美元衍生品交易。
八、隨機,是那座橋
回到最開始的那個問題:電腦裡的 random() 函數,究竟是什麼?
它是一個確定性的算法,偽裝成隨機,用於模擬我們無法直接計算的複雜現象。它足夠好,好到讓整個現代財務數學得以運作,讓選擇權可以被定價,讓風險可以被量化,讓不確定性可以被交易。
但它不是那個真實世界本身。
真實的股市有混沌在作用,有無數個體非線性交互的湧現效應,有我們尚未建模的系統性風險,有塔雷伯所說的那些「超出模型邊界的黑天鵝」。人工骰子能告訴你它描述的那個世界;它無法告訴你它沒有描述到的那個世界,還有多大。
這不是要讓你放棄這些工具,而是要讓你以正確的姿態持有它們。
隨機,是人類把混亂的世界翻譯成數學的那座橋。有了它,藥物的有效性可以被量化,選擇權的公平價格可以被計算,基因療法的安全邊際可以被估算。沒有它,統計是一堆感覺,金融是一場賭博,醫學是一門猜測的藝術。
有了它,世界變得可以計算——不是確定的,而是精確地不確定。
但使用這座橋的人,必須清楚地知道橋通向哪裡,橋的承重上限是多少,以及橋對岸的那個彼岸,是否就是他真正要去的地方。
最危險的不是不懂模型的人,而是對模型懂得恰好足夠用,卻不懂得模型的邊界在哪裡的人。他們把地圖當成了地形,把工具當成了真理,直到現實以它最殘忍的方式來糾正這個錯誤——通常,那個糾正來得毫無預警,來得又猛又快,來得剛好在你最沒有準備的時候。
這是使用任何工具之前,最基本的功課。
也是在市場面前保持長期存活的,唯一可靠的底層邏輯。
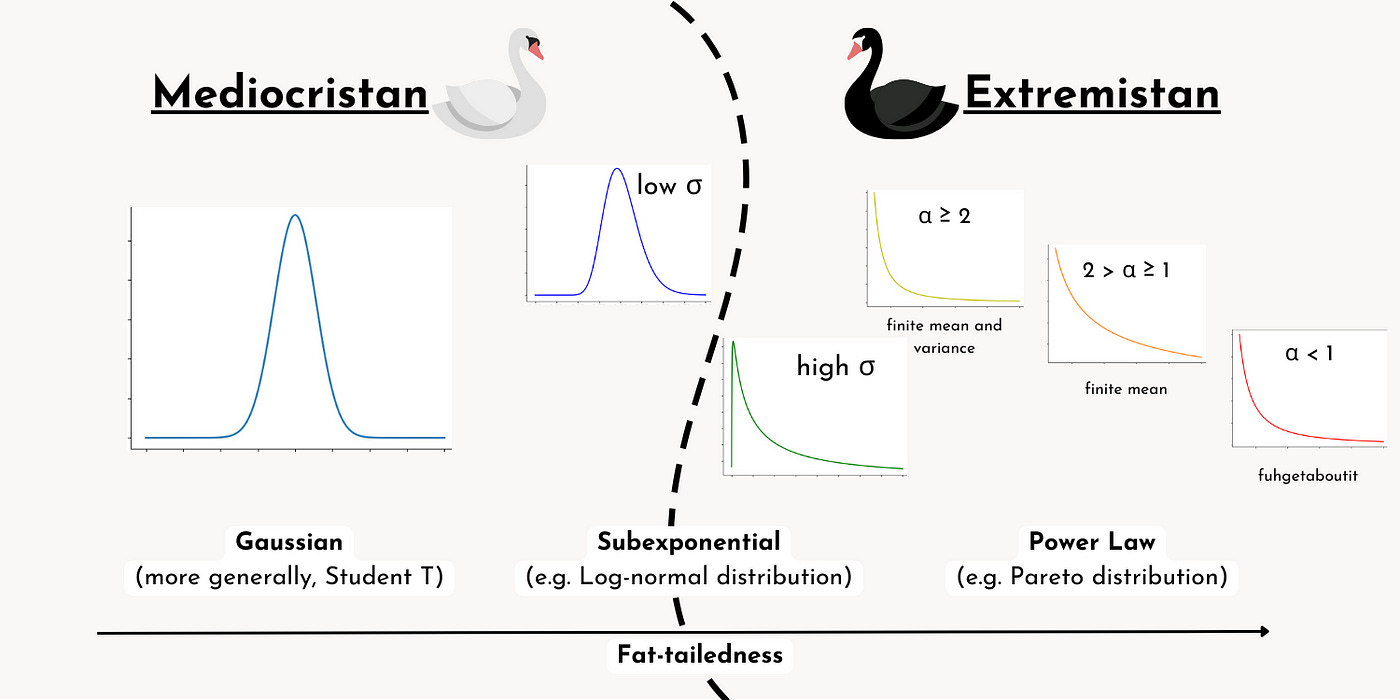
Nassim Taleb的《黑天鵝》簡單地說,就是認清金融市場是屬於「極端斯坦」,但歷年來每次重大金融危機,機構、對沖基金犯的錯,都是誤認市場是「平均斯坦」。
平均斯坦(Mediocristan),樣本內所有資料相差不大,罕有顯著異常的資料。
舉例:如果隨機找兩個成年男性的身高之和是3.5米,那麼大概率組合是兩個1.75米的,幾乎不會出現一個0.2米,一個3.3米的,所以,男性身高就屬於平均斯坦。
極端斯坦(Extremistan),樣本內所有資料差異性非常大。
舉例:如果隨機找兩個成年男性的年薪總和是1000萬,那麼大概率組合是一個990萬,一個10萬,因為普遍平均年薪在10萬左右,個別年薪會非常高,但幾乎隨機很難找到2個500萬工資的。所以,男性工資就屬於極端斯坦。
平均斯坦(Mediocristan)和極端斯坦(Extremistan)是Taleb在《Black Swan》這本書中特有的名詞
"真實市場裡從來不是免費的——它們是被你默默吞進去的代價,等到市場不再符合這些假設,帳單才會送來。而你往往不知道帳單什麼時候會來,因為你早就忘了當初欠下了這筆帳" 這個比喻實在是太貼切了,這篇文章寫得真好。
Hardcore好文