

在人工智慧蓬勃發展的今天,科學家們正不斷探索:機器是否能像人類一樣「看見」世界?這場追尋視覺真相的旅程,讓人類的智慧與靈長類大腦的奧秘交會,而其中的關鍵,竟然藏在一種我們日常少見、卻無所不在的技術——卷積神經網路(CNN)。
這不僅僅是科技的發展,更是人類試圖理解自己大腦運作的科學冒險。
一場從靈長類大腦啟發的科技革命
數十年來,神經科學家們不斷試圖解開大腦如何處理視覺訊息的謎團。透過觀察靈長類動物(例如獼猴)的視覺神經活動,他們發現,大腦的視覺皮層(Visual Cortex)以一種分層的方式處理影像資訊——從基本的邊緣、線條識別,一直到更複雜的形狀與物體辨識。這樣的分層機制,與現代 AI 中的卷積神經網路(CNN)竟然有著驚人的相似之處。

這引發了一個令人興奮的問題:如果 CNN 的架構和靈長類大腦如此相似,那麼,是否能直接用 CNN 來模擬人類視覺?甚至,預測大腦對影像的反應?
科學家決定一探究竟。
當機器「看見」——人工智慧預測大腦反應?
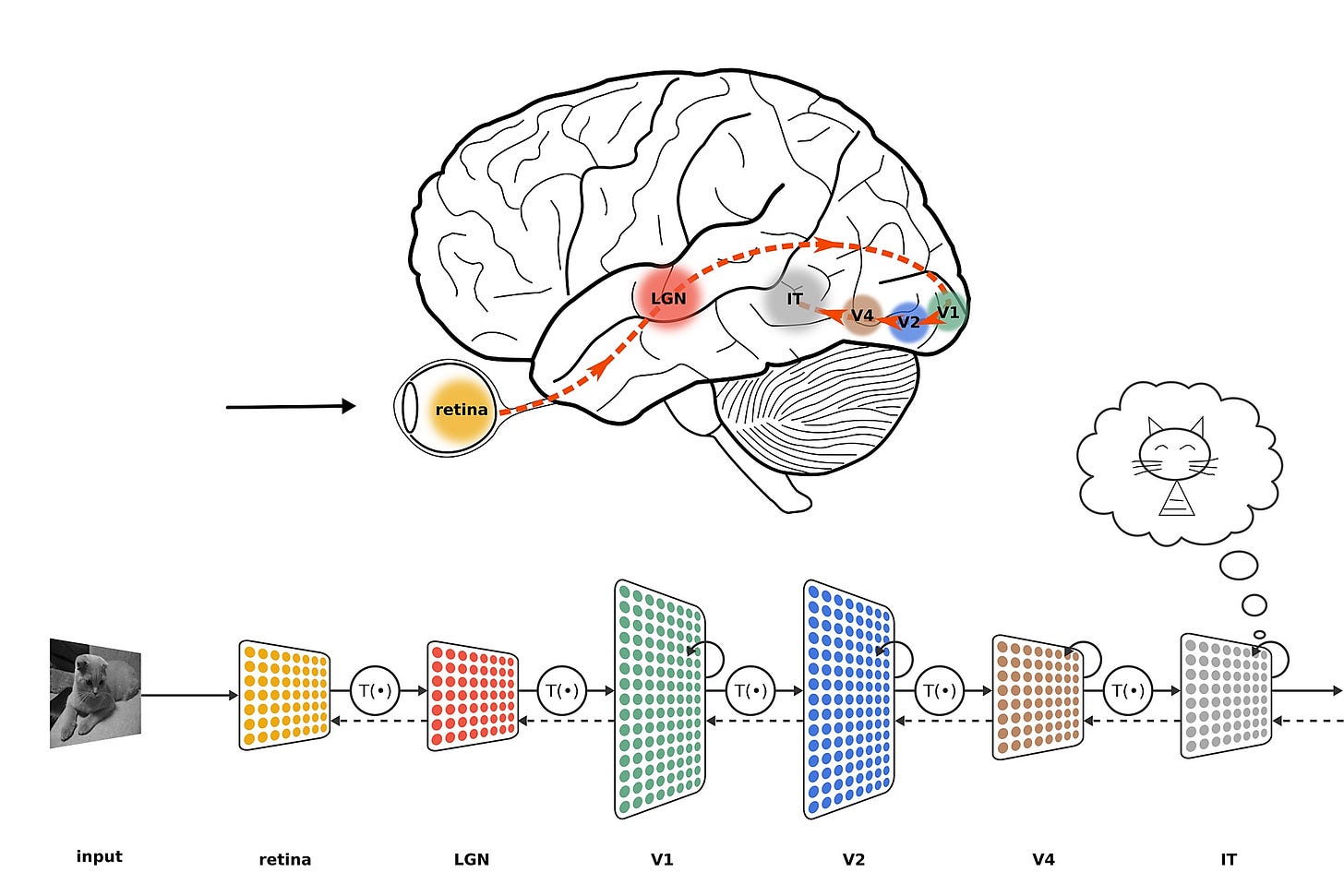
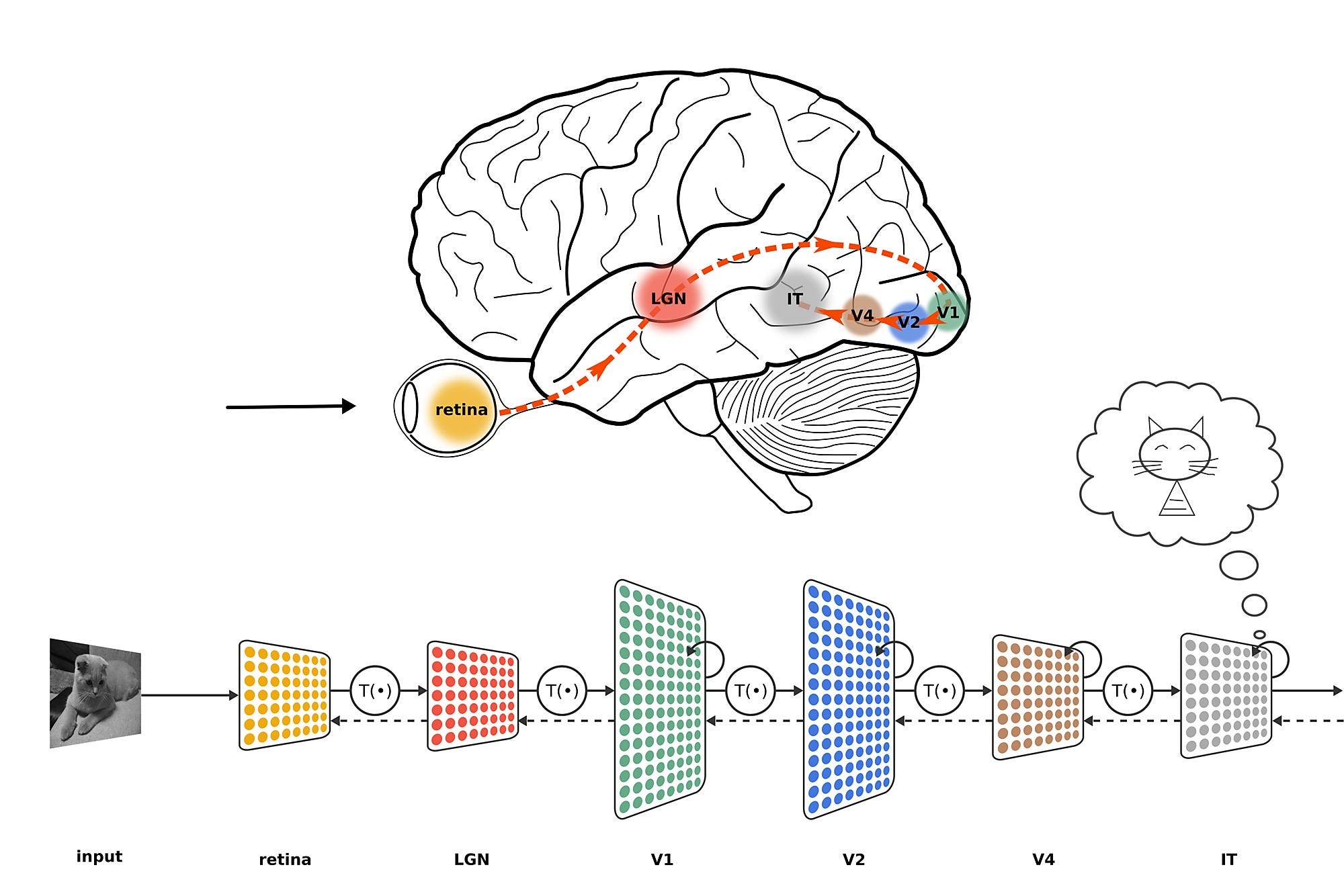
研究人員利用 CNN 來預測靈長類大腦(包括人類與獼猴)的神經反應,結果令人震驚:即使不經過訓練,只是隨機設定權重的 CNN,也能準確預測初級視覺皮層1(V1)的活動! 這代表 CNN 的結構本身,就已經足夠接近大腦的視覺處理機制。
但當研究深入到更高級的視覺區域2,例如負責物體識別的顳下皮質(IT),情況就變得複雜了。這些區域的神經活動,無法單靠隨機權重來模擬,必須透過大量學習與訓練,才能真正達到類似的辨識能力。換句話說,大腦高階視覺區域的運作,遠比初級視覺區更依賴學習與經驗。
機器與大腦的分水嶺——「訓練」的重要性
在這場 AI 與大腦的較勁中,研究人員發現了一個關鍵因素:模型的複雜度。當 CNN 的結構變得更精密,特別是當它使用 ReLU 激活函數 和 最大池化 操作時,它就能更準確地模擬 V1 的神經反應。而這種準確性,與大腦的生物機制不謀而合。
但對於高階視覺區域來說,這樣的架構並不足夠,還需要經過訓練的權重配置,才能真正捕捉到大腦辨識物體的精細特徵。這種現象與人類的學習過程相似——我們從小不斷觀看、辨識、分類物體,最終形成穩定的視覺認知。而 CNN 也必須經歷類似的「學習」過程,才能真正掌握物體識別的能力。
視覺的兩條道路:紋理 vs. 物體識別
那麼,如果 CNN 在沒有訓練的情況下,仍然能模擬 V1,它到底能做些什麼?研究人員進一步測試發現,隨機權重的 CNN 在「紋理識別」方面表現優異,但在「物體識別」上卻遠遠落後。
這似乎印證了大腦的視覺處理也有兩條不同的路徑:
低階視覺(V1):更傾向於處理 紋理、邊緣與形狀特徵,這些屬性是天生存在於視覺系統的,不需要額外學習。
高階視覺(如 IT):專注於 物體識別,並且高度依賴學習經驗。這類區域需要透過不斷的影像刺激與神經調整,才能發展出成熟的辨識能力。
這項發現為視覺神經科學提供了新的視角,也讓我們對 AI 的未來發展充滿想像。
模仿大腦,我們還有多遠?
當研究人員用 Gabor 斑塊(常用來測試視覺神經元的方向選擇性)來刺激 CNN 時,他們驚訝地發現:CNN 中的某些神經元展現出了與 V1 神經元相似的方向選擇性。這意味著,即使是一個隨機初始化的 CNN,也能部分再現大腦的視覺特徵選擇性!
然而,這並不代表 CNN 已經完全模仿了人類視覺。雖然它能捕捉 V1 的一些特徵,但在更高級的視覺處理方面,仍然無法與大腦相比。這提醒我們,AI 雖然強大,但與大腦的學習與適應能力仍有巨大差距。
LGN(外側膝狀體,Lateral Geniculate Nucleus)是人類視覺系統的關鍵環節,它不只是視網膜與大腦之間的「訊號中繼站」,更是一個能夠「篩選」與「調節」視覺訊息的處理中心,確保我們的大腦專注於最重要的視覺資訊。這個小小的結構,讓我們能夠高效地感知世界,從動態的車流到色彩繽紛的日落,一切都從這裡開始。
視網膜 → LGN → V1(初級視覺皮層)
LGN 主要負責過濾、整理和加強視覺訊息,確保大腦接收到重要的視覺資訊,而非所有雜亂的輸入。
初級視覺皮層(V1)位於大腦的枕葉(Occipital lobe)。負責接收來自視網膜的視覺資訊,透過視神經傳遞到視丘(LGN),再傳送到 V1。是視覺訊息處理的第一站,負責基本特徵的分析,如邊緣、對比、方向、運動、顏色等。之後,視覺訊息會進一步傳遞到高階視覺區域(如 V2、V4、IT 等)進行更複雜的物體識別與理解。V1 是視覺感知的重要起點,許多神經科學研究都圍繞它進行,因為它能反映視覺系統最基本的計算方式。
高階視覺皮層區域包括:V2(次級視覺皮層)、V4(負責顏色與形狀)、MT/V5(負責運動感知)、IT(顳下皮層,負責物體與面孔辨識)。
V2對V1提供的基本視覺資訊進行更進一步的處理,處理邊緣、輪廓、深度線索等資訊。V4的功能包含顏色感知(Color perception)、形狀辨識(Shape recognition)與物體辨識(Object recognition)。MT/V5的功能包含運動感知(Motion perception)、追蹤移動的物體、深度與速度的計算。
IT位於腹側視覺通路(Ventral Stream)。其功能包含物體辨識(Object recognition)、面部辨識(Face recognition)、高階視覺記憶(與大腦中的長期記憶和認知聯繫)。