

GenAI演進之路:關鍵技術里程碑
過去這十年,對於AI可算是一段人類腦力大爆發,激動人心的時刻。從對深度學習潛力的各種驚喜探索,到最終引發GenAI全領域的爆發式增長。本文沿著記憶的軌跡回顧過去超過一甲子時間,重新審視GenAI一路走來的重要里程碑。
前言
在交大攻讀研究所期間,我曾對當時流行的類神經網路抱有偏見,因而未加入那位教授的研究室,反而選擇了偏向數理統計的研究方向。我的論文探討時間序列,涉及股價與總體經濟的關係。當時,我認定類神經網路是「偽科學」,認為學好線性代數、機率與統計才是正統之道。殊不知,當時的神經網路研究正處於隧道深處,距離曙光僅咫尺之遙。那個實驗室的同學們,日後成為微軟台灣總經理、鉅亨網總經理、Google副總經理、富邦銀行香港財富管理總經理,還有交大傑出校友及交大資工傑出系友等。多年後,我才意識到這個實驗室真是人才輩出。
三年前,我投入時間深入了解機器學習,並順利取得IBM Professional Data Scientist證照。當時我自以為深度學習不過是機器學習的延伸,卻未料到這是截然不同的知識領域。後來重返台大進修,終於有機會坐在課堂上系統地學習。
秉持著向Elon Musk學習的精神,堅持追求知識的第一性原理,我深信GenAI(生成式AI)將徹底顛覆未來的工作模式並重塑世界。GenAI如此強大,其知識積累的過程究竟經歷了哪些重要的里程碑?我花了兩週時間仔細梳理,試圖整理出這段歷程。如果你也想探究這段精彩的知識之旅,歡迎跟隨本文一同探索。
在整個AI革命的背後,蘊藏著一個深刻的理念:模式預測可以引導智能。機器所感知或聽到的一切、它所執行的每個動作,甚至思想本身,都可以透過模式來理解。一旦機器學會預測這些模式,它便能創造出新的模式,進而模仿並常常超越人類的能力。
可以說,自然界在三個不同的層次上解決了學習問題。第一層是進化學習,它基於一個簡單的策略:嘗試隨機的變異,並保留那些能夠存活下來的變異。然而,這是一個極為緩慢的學習過程,跨越數代進行,難以適應生命中快速的環境變化。於是,自然界演化出了第二層學習,其速度快得多——利用大腦在個體的生命週期內適應行為。大腦使生物能夠進行隨機探索,並根據獎勵或痛苦的經驗,選擇更有效的行為,這便是所謂的強化學習。這一機制構成了AI範式——機器學習的基礎。我們不再試圖透過指令來編程機器,而是讓它從零開始,通過學習信號來掌握一切。
早在1960年代,當時在MIT任職的Donald Michie展示了他的第一台強化學習機器。這台機器利用火柴盒和彩色珠子來玩井字遊戲(Tic-Tac-Toe):每個火柴盒代表一個特定的棋盤狀態,內含的彩色珠子則對應於從該狀態出發的各種可能移動。遊戲的玩法十分簡單:當你走完一步後,操作員(當時尚無電腦)會找到對應當前棋盤狀態的火柴盒,隨機抽出一顆珠子,珠子的顏色決定機器的下一步移動。如果機器贏得比賽,便會在該場遊戲中所有移動對應的火柴盒中,添加更多獲勝顏色的珠子,以強化這些動作;反之,若輸掉比賽,則移除相應的珠子。透過這一簡單的基於獎勵的過程,機器逐漸發現了完美的遊戲策略。這些獲勝的策略並非透過編程預先設定,而是從經驗中自然湧現的。
(關於這個遊戲 MENACE(Matchbox Educable Noughts and Crosses Engine)的介紹,Youtube連結在此)

雖然這表明機器可以學習,但它有一個關鍵限制:每種可能的情況或棋盤狀態都需要一個單獨的盒子,由人類選擇。要真正模擬大腦,機器需要自己的感知能力,也就是自行識別模式的能力,這就是我們所說的抽象(abstraction)。形成抽象是你自動進行的行為,忽略瑣碎的差異,專注於潛在的相似性。抽象讓你能夠忽略無關緊要的差異,關注事物背後的共同模式。
為了打造一台能學習抽象的機器,研究人員從自然界尋找靈感。在19世紀末,腦科學家發現,大腦是一個由神經元組成的龐大網路。來自五官接受到的信息,深入大腦層次進行處理,神經元分層次發射,形成連鎖反應,構成一連串的活動模式。當看到一隻貓或一隻狗時,如果觀察大腦第一層的神經元,依這些模式,起初很難區分是貓是狗,但隨著信號穿過更深層的大腦,它們開始分離成不同的激活模式1。到最深層時,貓和狗觸發的是完全不同的神經元群。事實上,你所有的思想都以深層腦中的獨特激活模式存在。一個思想就是一大群神經元中的活動模式。事實上,科學家現在可以透過觀察人的大腦活動,知道實驗者正在想什麼圖像。
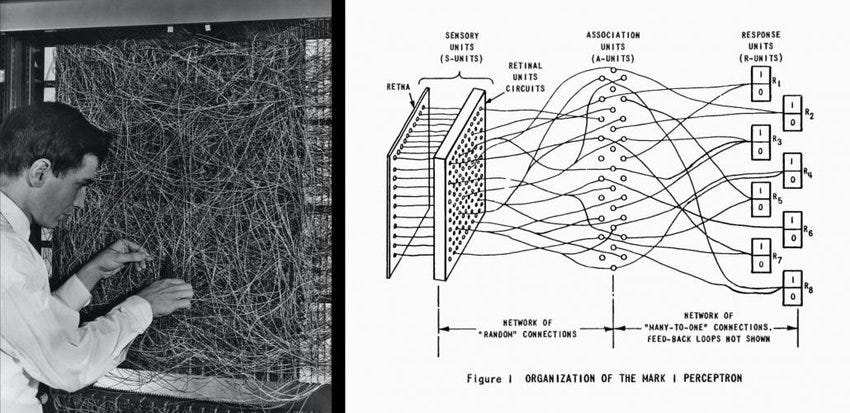
上圖是Frank Rosenblatt在1958年試圖打造的——由電子元件組成的人工腦組織。他使用電晶體(一種微型的電子開關)作為人工神經元,並將其連接成一個三層網絡。第一層連接到一個人工視網膜,負責讀取圖像中的像素點;隨後的層次則採用隨機連接,並通過學習過程逐步演化。網絡的輸出極為簡單:僅有兩個燈泡,其中一個代表「正方形」,另一個代表「圓形」。Rosenblatt的網絡依賴於試錯學習法,每個神經元之間的連接強度由一個調光旋鈕控制,該旋鈕調節電流的大小,模擬大腦中神經連接的增強或減弱。
起初,當網絡接收到一張圖像時,它無法準確判斷圖像的形狀,會同時激活代表圓形和正方形的輸出。為了訓練網絡,Rosenblatt會微調每個連接的旋鈕,觀察輸出的變化,並保留那些有助於正確識別的調整。經過足夠多的訓練樣本後,網絡便能獨立識別模式,無需再進行手動調整。這種通過調整權重並保留有益變化的方法,正是當今所有AI學習算法的基礎。在這個網絡中,某些神經元學會了對曲線產生敏感反應,而其他神經元則專注於檢測邊緣,這與人類大腦的運作方式類似。

關於 Rosenblatt 的感知網路介紹,連結在此。

到1980年代末,Yann LeCun 展示了大型神經網絡的潛力,成功解決了業界面臨的一項實際問題——快速識別信封上的手寫地址。他訓練了一個網絡,透過數千個樣本學習識別手寫數字。與 Rosenblatt 的網絡類似,其早期層次負責檢測基本的曲線和邊緣,而更深層次則構建了一個層次結構,將這些簡單的模式組合成更複雜的特徵,例如環形檢測器,最終形成數字檢測器。這個過程將無數的手寫變體轉化為九種可能的數字輸出。

為了深入理解這些網絡內部的工作機制,我們可以可視化它們如何在空間上組織信息。在網絡的第一層,相似的對象(例如不同的手寫數字「2」)是隨機分散的。然而,隨著信號穿過各個層次,網絡學會了轉換這個空間,逐漸將相似的樣本聚集在一起。到了最後一層,所有的「2」會聚集在一個區域,所有的「3」則聚集在另一個區域,形成我們所謂的「概念區域」。這一現象為我們提供了一個深刻的洞見:一個概念在本質上就是空間中的一個區域。

然而,這種方法直到2012年的ImageNet比賽才迎來了真正的突破。ImageNet是一個年度競賽,旨在挑戰研究人員創建能自動識別圖像內容的電腦程序。來自多倫多大學的團隊2將Yann LeCun的技術擴展到前所未有的規模,他們利用數百萬張標記圖像訓練自己的神經網絡,並發現了一些令人驚嘆的現象:儘管網絡的早期層次仍專注於檢測邊緣、曲線和基本形狀,但更深層次卻能識別出越來越複雜的模式——如紋理,甚至是面部特徵。這一發現解釋了為何兩張像素完全不同的狗的圖像,在第一層會激活截然不同的神經元,但在更深層次卻能觸發相同的「狗」神經元。

這個神經網絡完全依靠自身學習,無需人類編程,最終在圖像識別任務上超越了人類的表現。這一成就,在比賽前夕,幾乎無人預料。該方法被稱為深度學習,其核心論點無可辯駁:只要神經網絡足夠深且規模足夠大,它就能被訓練來解決極其困難的任務。關鍵在於「深度」和「規模」。起初,學界並未重視大型神經網絡的潛力,然而,正是這種對模式識別的深入探索,帶來了革命性的突破。
下一個重大進展源於一個關鍵的轉變:訓練神經網絡的目標從識別轉向了預測。1992年,Gerald Tesauro 在這一理念的基礎上,開發了一個能夠玩雙陸棋的神經網絡。與傳統方法不同,這個網絡並未依賴人類設計的規則,而是被訓練來根據給定的棋盤狀態,輸出勝利的概率。透過無數次自我對弈和基於勝負的獎勵信號,網絡學會了識別出能夠帶來勝利的棋盤模式。它甚至發現了一些連專業玩家都感到驚訝的策略。從預測勝率到生成行動的轉變自然而然:網絡開始輸出所有可能下一步動作的概率,並將最高概率的動作視為最佳選擇。很快,神經網絡在各類遊戲中——如西洋棋、圍棋、電子遊戲乃至策略遊戲——逐漸擊敗了人類。


然而,這些成就僅限於相對簡化的環境。真正的挑戰始終在於應對現實世界的複雜性,例如物理機器人技術。OpenAI(當時還是一個影響力有限的小型研究實驗室)提供了一個極佳的例證。他們堅信,模式學習的原則同樣適用於現實世界的問題。為驗證這一觀點,他們訓練了一隻機器手來操作一個立方體。與傳統方法不同,他們並未編寫任何具體的動作指令,而是採用了一個大型神經網絡:該網絡以圖像作為輸入,學習輸出動作的概率——具體而言,是各種馬達動作的下一步選擇。通過數百萬次的嘗試和模擬,系統獨立發現了成功的操作模式,其最終展現的行為驚人地類似於人類。
在更為複雜的任務中,如機器人足球,網絡從零開始學會了走路、踢球,甚至能預測對手的射門並及時攔截。所有這些複雜的行為皆源自同一個學習過程。這正是行為抽象的體現:儘管每次足球射門的細節各異,網絡卻能捕捉到導致成功的潛在動作模式。然而,這些網絡的抽象能力仍相當有限——每個網絡僅針對特定任務進行訓練,導致它們只能在單一領域內表現出色。
2016年,非監督式學習(Unsupervised Learning) 仍是機器學習領域中一個尚未解決的難題,當時無人確知如何有效實現這一目標。最終的突破源於AI達到了自然界學習的第三層次——語言。語言之所以成為AI進化的下一階段關鍵,是因為它賦予了AI從他人經驗中學習的能力。有了語言,AI擁有了通用的想像力,能夠構想任何可以用文字表達的事物。相較之下,遊戲AI僅能設想棋盤上的走法,而語言則開啟了無限的可能性。
要實現這一突破,必須追求一個宏大的目標:理解語言本身。這一挑戰的關鍵洞見來自信息論之父克勞德·香農(Claude Shannon)。早在1940年代,香農提出將語言視為一系列預測過程——每個詞的出現都是基於前文從多個可能詞語中選出的結果。基於這一理念,1980年代,研究人員開始訓練小型神經網絡來預測文本中的下一個詞,類似於讓網絡學習預測遊戲中的下一步動作。這些網絡不僅學會了預測下一個字母,還展現出驚人的能力:它們能自動將相似的詞彙聚集在一起,例如動詞與動詞、名詞與名詞,甚至是意義相近的詞語。
2015年,Andre Karpathy 證明了這一方法的潛力。他發現,當在大量文本數據上訓練時,這些網絡不僅能預測模式,還能生成模式。他透過輸入一個起始短語,並將輸出循環回輸入,讓網絡延續所學模式,進而生成連貫且風格多樣的文本——從莎士比亞式的文學到數學論述,成果令人震撼。次年,OpenAI的Alex Radford 將這一實驗推向新高度,訓練了一個更大的網絡,基於數百萬條亞馬遜網站的評論數據。他們發現,網絡能從簡單的語法結構逐步構建出複雜的語義概念,例如一個著名的「情感神經元」,能夠比當時的專業系統更精確地檢測評論中的正面或負面情感。
這一發現直接促成了 GPT(Generative Pre-trained Transformer)系列 的誕生。GPT模型完全依靠自身學習理解了語言的奧秘。OpenAI意識到這一技術的深遠影響,隨即探索更大規模模型的潛力。他們採用了一種名為「Transformers」的新架構,這種架構能以前所未有的效率處理模式。其特點在於,當數據通過每一層時,網絡能動態形成神經元之間的連接,使單一層次完成過去需要多層才能實現的工作。這一創新最終促成了 GPT-1 的誕生——當時規模最大的語言模型,其訓練目標是預測數千本書中的下一個詞,這是迄今為止最具通用性的訓練設計。結果令人驚歎:GPT-1不僅能連貫地延續任何給定的文本片段,還能回答訓練文本中未曾出現的問題。這一現象進一步證實,簡單的預測任務正逐步引導模型走向真正的語言理解。
隨著GPT的每次新版本,神經網絡的規模不斷擴大,訓練數據也日益豐富,從書籍到互聯網,最終涵蓋了人類知識的廣泛領域。GPT-3展現了一些令人驚嘆的能力,例如著名的「wug測試」(一種用於兒童的語言測試)。只需向模型描述一個新概念,它就能立即自然地加以運用,這種能力被稱為上下文學習。這種從新例子中學習的能力適用於任何指定的任務,類似於人類快速掌握新概念的方式。這意味著,只要加以描述,你就能從神經網絡中獲得所需的任何行為。
ChatGPT的公開亮相標誌著一個重大的突破。它在GPT-3的基礎上進一步訓練,採用強化學習來評估其輸出,判斷其是否準確遵循指令或進行合理推理。這使得ChatGPT在指令遵循和推理能力上表現更為出色。與人類相似,這些系統在被允許「大聲思考」並逐步推理時,能夠產生更優質的結果。實驗表明,與其一味追求建造更大的模型,簡單地延長系統的思考時間,就能顯著提升其表現。這標誌著我們進入了一個全新的計算時代,機器開始在概念和詞語層面進行運作。
這種方法迅速超越了語言領域的限制。研究人員發現,幾乎所有信息都可以被視為某種序列:歌曲分解為音符,視頻分解為幀,動作分解為移動。例如,Transformer網絡透過預測下一個音符來生成音樂,每個注意力頭負責識別音樂中的不同模式。注意力頭數量越多,網絡的能力就越強大。這種架構能夠同時關注所有元素。如今,一個模型不僅能理解用詞語給出的指令,還能生成相應的圖像和視頻,並指導機器人執行對應的動作。這意味著機器人能夠透過想像,練習用詞語描述的物理動作。
現在的問題在於:我們的AI是否具備足夠的結構和世界建模能力?我個人認為完全足夠。例如,Runway(一個AI模型)在內部表徵方面已達到當前的先進水平。這種跨越視覺、聲音和動作的統一理解,反映了人類大腦的工作方式,因為它們的核心都是基於可預測和生成的模式。從進化的簡單原則「嘗試並保留有效的方法」,到從直接經驗中學習,再到通過語言學習,AI已經實現了自然界的第三層智能——靈活的想像力。這一進展的速度遠超所有人的預期。
然而,奇點(Singular,即AI超越人類智能的時刻)或許不會以戲劇性的接管形式突然發生,而是可能悄無聲息地滲入我們的生活,隨著AI逐漸重塑世界,一個模式接著一個模式。領先AI實驗室的創始人,包括OpenAI的成員,現在表示,我們比以往任何時候都能更清晰地看到通往人工通用智能(AGI)的道路。關鍵問題不在於我們是否能實現AGI,而在於我們將如何部署它。這些AI代理就像數位勞動力,與你的員工並肩工作。你向它們展示工作成果的範例,它們會嘗試生成相應內容,並由你提供反饋和限制。我們正步入一個充滿巨大不確定性的時代,當我們開始與比我們更智能的實體互動時,未來將變得難以預測。
最終,智能的未來——無論是人工的還是人類的——可能並不取決於機器是否真正理解世界,而是取決於我們選擇接受的模式,以及更重要的,我們賦予它們的自主權。
感謝分享。一般認為,即便是在LLM 被廣為大眾所知之後,LLM 本身在短短三年多的時間,也經歷了三次巨大的變化:
1. ChatGPT 時刻:標示著LLM 走進了大眾的視野,成為所有人都無法忽視的一個社會現象
2. CoT 推理鏈創造:經由 Chain Of Thoughts 讓LLM 有足夠的時間思考,最後的結果有質的飛躍,而且思考的時間越長,通常獲得的結果也越佳
3. Agentic AI 的興起:當使用 CoT ,加上把上一次的結果喂回給LLM,發現AI 能夠自主完成複雜的任務,完全不需要或只需要人類少量的介入。這標示著AI 真正的進入自主完成以前被人認為只有人類能夠完成的工作。
既便只有短短的三年,就已經發生了這麼多的進步,這在之前的科技發展也是無法想像的