

在談論人工智慧的當下,我們往往沉迷於模型參數的爆炸性增長,或是驚嘆於生成式 AI 類人般的對話能力,卻鮮少意識到這場智慧革命背後,正上演著一場波瀾壯闊的硬體演化史。AI 不僅僅是漂浮在雲端的程式碼,它是有重量、有溫度,且嚴格受制於物理定律的實體存在。
從早期的 RNN 到如今統治世界的 Transformer 架構,演算法的每一次躍進,都在對底層算力提出全新的拷問。當數學家將計算圖從「時間序列」改寫為「空間矩陣」,晶片設計師便被迫推翻舊有的邏輯,重新排列億萬個電晶體的佈局。這是一場由軟體定義硬體、再由硬體反向制約軟體的雙向博弈。
本文將帶領讀者穿透表層的喧囂,深入技術的核心肌理。我們將從 RNN 的結構性困局出發,解析 Attention 機制如何引爆並行運算的革命,進而探討這場數學變革如何重塑了 GPU、TPU 與 ASIC 的設計哲學,並最終將競爭的戰場推向了記憶體頻寬(HBM)與資料互連的物理極限。這不只是一篇關於晶片技術的分析,更是一份解讀現代算力地緣政治的底層邏輯導航圖。
歷史的轉折:RNN 為什麼無法支撐今天的 AI?
在 Transformer 橫空出世之前,自然語言處理領域的絕對王者是遞歸神經網路(RNN)及其變種 LSTM 與 GRU。它的運作哲學非常符合人類直覺:一次讀一個字,將當下的理解作為「狀態」(State)傳遞給下一步,以此記住過去、理解未來。
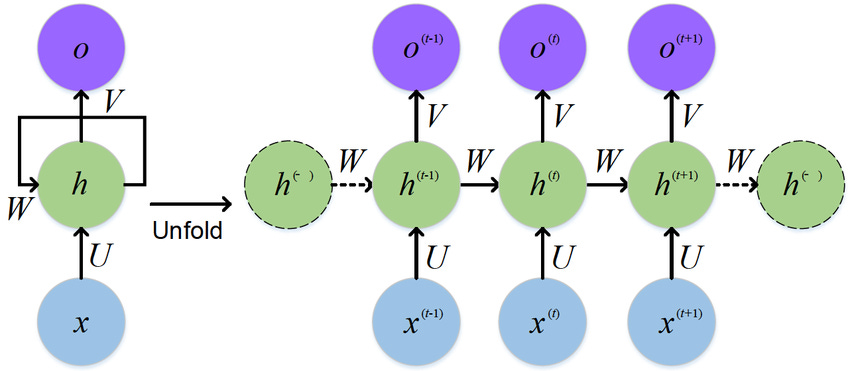
然而,這種看似合理的邏輯,在設計上卻犯了一個致命的錯誤:每一步都絕對依賴前一步。
這一點可以從 RNN 的核心公式中看出:
在這個公式中,ht(當前狀態)的計算必須等待 ht-1(前一刻狀態)完成。這種數學特性帶來了三個嚴重的副作用:
時間相依性(Sequential Dependency): 在計算第 5 個 token 之前,系統必須先算完第 4 個。這意味著計算過程被鎖死在時間軸上,無法跳躍。
無法並行(No Parallelism): 即使你的 GPU 擁有 20,000 個運算核心,在 RNN 的架構下,大多數核心只能處於待命狀態,因為任務無法拆解。

梯度問題(Gradient Vanishing/Exploding): 在長序列中,誤差訊號需要穿越漫長的時間鏈條反向傳播(Backpropagation),這導致訊號容易在途中「消失」或「爆炸」,使模型難以學習長距離的關聯。



簡而言之,RNN 本質上是一條「很長、很窄、很慢」的計算管道。隨著資料量與模型規模的指數級增長,RNN 的天花板並非來自數學理論的不足,而是來自計算圖(Computational Graph)的結構性限制。
二、Attention 的橫空出世:一次看全部
2017 年,Google 團隊發表的論文《Attention Is All You Need》改變了一切。這篇論文的核心思想只有一句顛覆性的話:模型不必按順序閱讀,每個詞可以直接「看見」整句話。
這就是 Self-Attention(自注意力機制)1。
它徹底改寫了計算圖的結構:不再是依賴時間順序的「接力賽」,而是一場所有詞彙同時發聲的「大合唱」。所有的輸入可以同時進入模型,並行計算彼此之間的關聯性。
三、自注意的關鍵數學:Softmax、餘弦相似度與多頭
要理解為什麼 Transformer 能釋放算力,必須理解其數學核心。
1. 相關性來自「投影空間」
在 Attention 機制中,每個詞都會被轉換成三個向量:
Q (Query): 你想查詢什麼?
K (Key): 這個詞的特徵是什麼?
V (Value): 這個詞的實質內容是什麼?
運算的靈魂在於這條公式:
這裡發生了三個關鍵步驟:
Q 與 K 做點積(Dot Product): 本質上這就是在計算「餘弦相似度」。模型在問:「這兩個詞的關係有多緊密?」
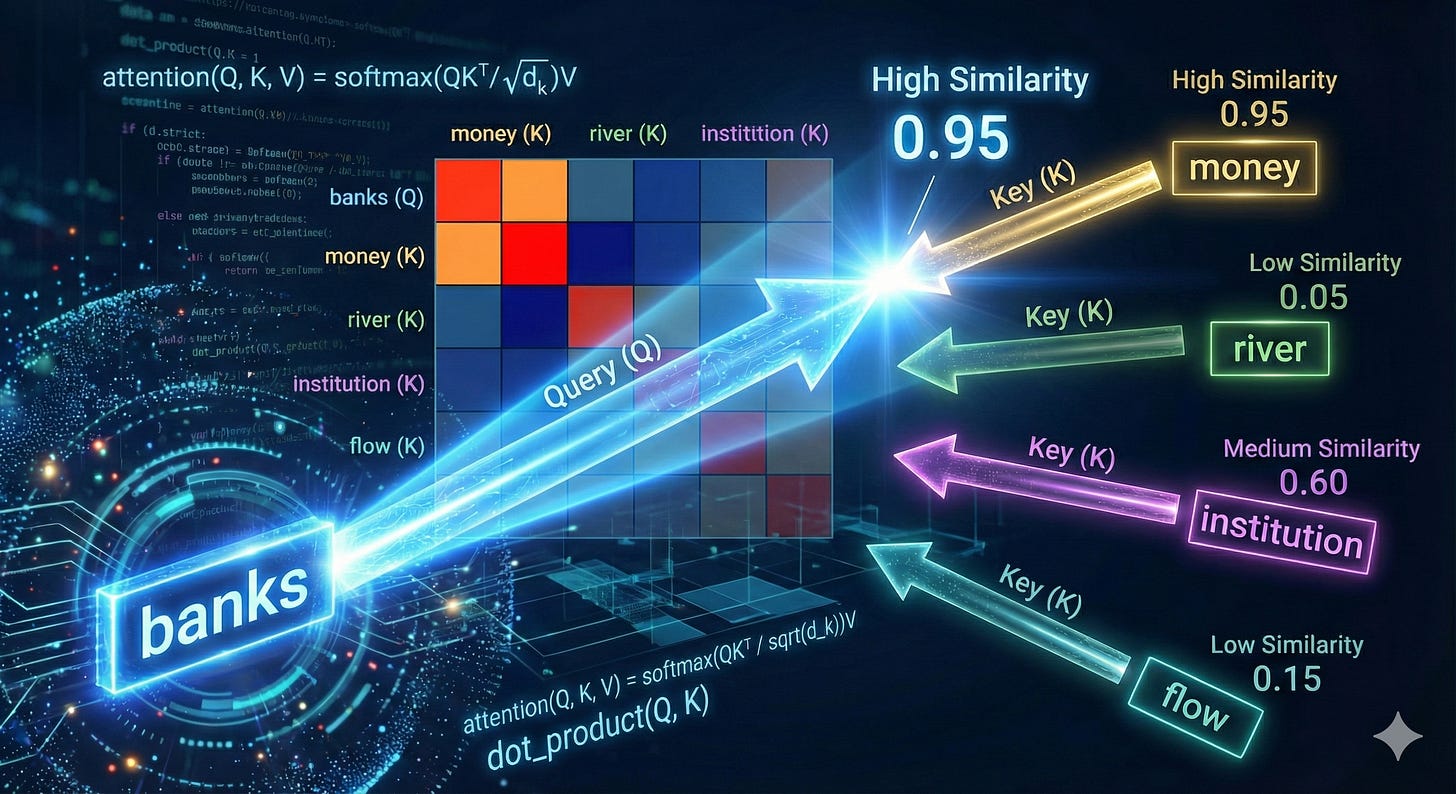
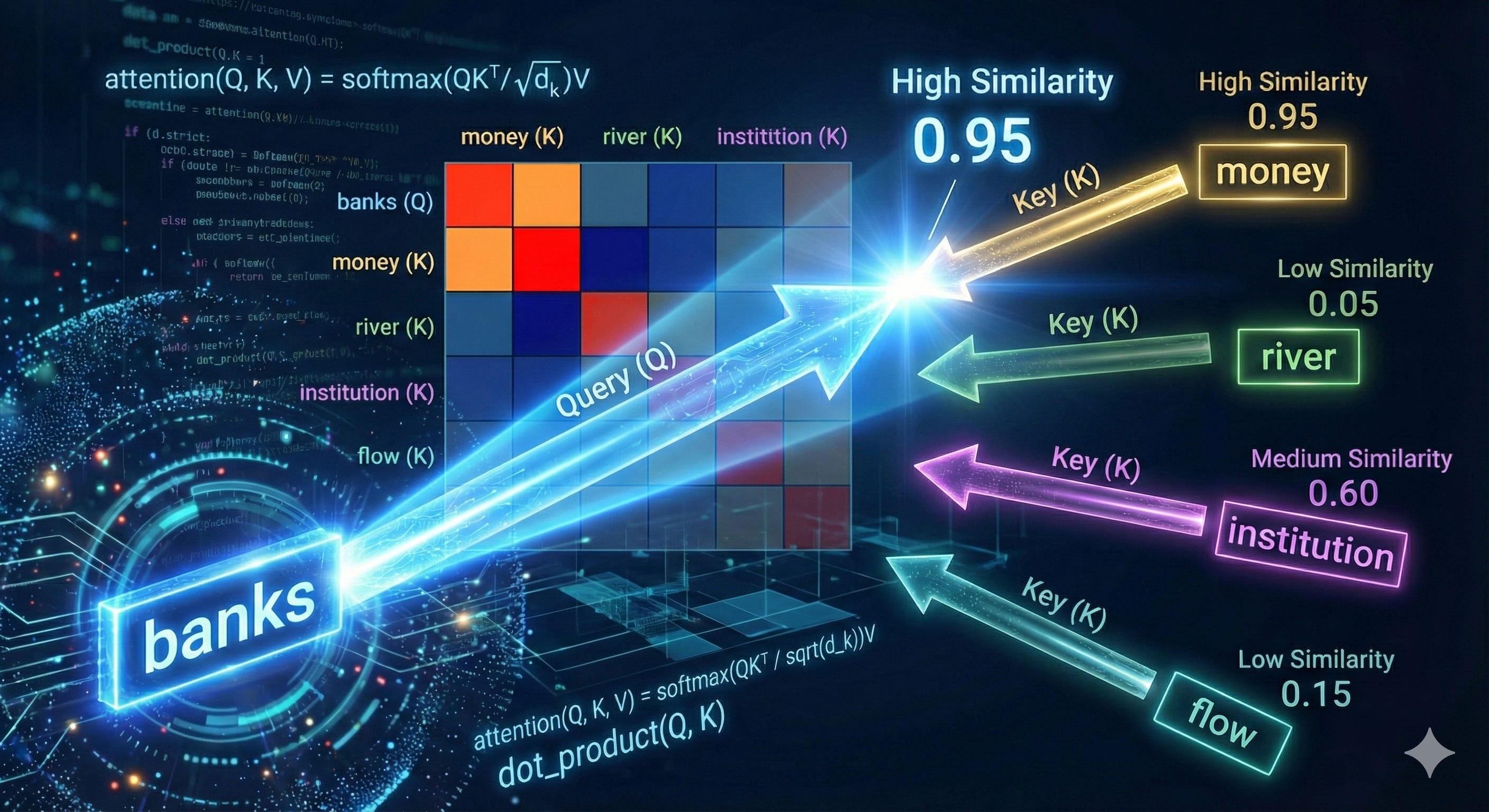
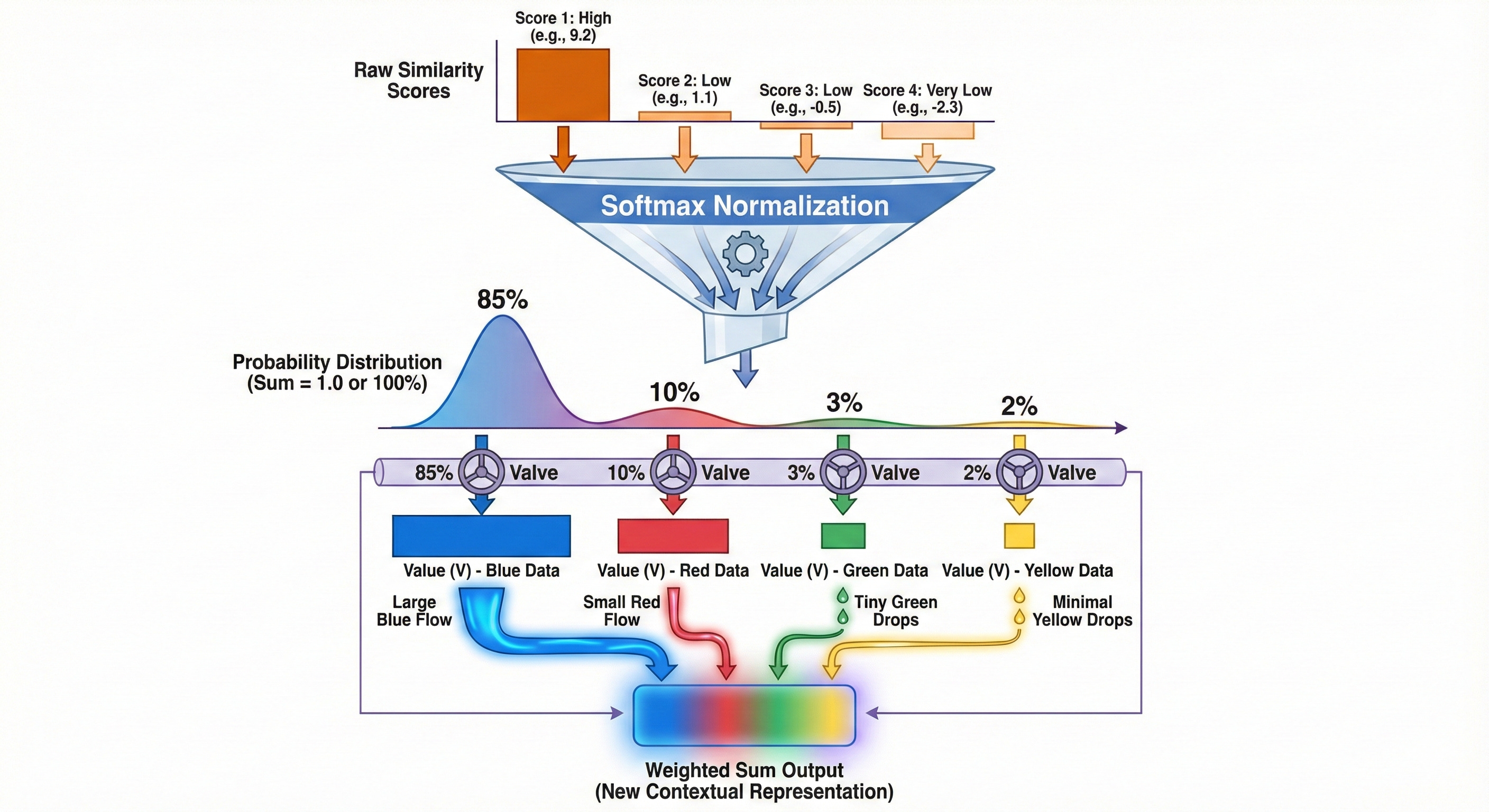
尋找相關性——Q 與 K 的點積餘弦相似度:Attention 機制的第一步:計算兩個詞之間的潛在關係強度。「查詢 (Query, Q)」向量如何像一道探照燈一樣,在向量空間中掃描其他的「鍵 (Key, K)」向量。數學上的「點積(Dot Product)」在此被轉化為直觀的「方向一致性」(也就是餘弦相似度)。 Softmax 標準化: 將計算出的相似度分數轉化為機率分佈(權重),讓強關聯的詞獲得高權重,弱關聯的歸零。
加權 V: 用這些權重去提取 Value 中的資訊。
2. 多頭注意力(Multi-Head)的立體視角
Transformer 不僅僅做一次 Attention,而是將其拆分為多個「子空間」(Heads)。這就像是讓模型戴上不同的眼鏡:
有的頭專門關注語法結構。
有的頭專門捕捉語意關聯。
有的頭專門尋找長距離的依賴關係。
這種設計讓語言理解從平面變得立體,且所有計算皆可並行處理。

四、革命真正的起點:Self-Attention 帶來的三個算力訊號
Transformer 的成功,不僅是因為它更聰明,更是因為它的計算方式終於與現代晶片架構完美匹配。它向硬體界發出了三個關鍵的「算力訊號」,決定了後續硬體發展的命運:
1. QKV 訊號 —— 矩陣乘法成為主角
在 Transformer 模型中,80% 至 95% 的浮點運算(FLOPs)都是在執行 GEMM(通用矩陣乘法)。
這導致了通用 CPU 的衰落與加速器的崛起。CPU 擅長的複雜控制邏輯在這裡變成了包袱,而專門處理大規模矩陣運算的加速引擎成為了必需品。
2. Vector 訊號 —— 那 5% 的瓶頸
雖然矩陣運算佔了大頭,但 LayerNorm、Softmax 和 RoPE(旋轉位置編碼)等操作屬於逐元素(Element-wise)的向量運算。
根據阿姆達爾定律(Amdahl’s Law),無論矩陣單元多強大,如果向量處理單元跟不上,整體的運算速度仍會被這 5% 的低效運算拖慢。這迫使晶片設計必須兼顧矩陣與向量的平衡。

3. KV Cache 訊號 —— 推理時的真正戰場
這是目前 AI 推理面臨的最大挑戰。在生成文字時,每生成一個新的 token,模型都需要讀取整段歷史對話的 Key 和 Value。
這導致了一個現象:推理的瓶頸往往不是算力,而是記憶體頻寬。 HBM、記憶體帶寬與延遲,突然超越了運算核心,成為主角。

五、從算法到架構:晶片世界被迫重排
為了響應上述訊號,晶片巨頭與新創公司分別走上了不同的道路:
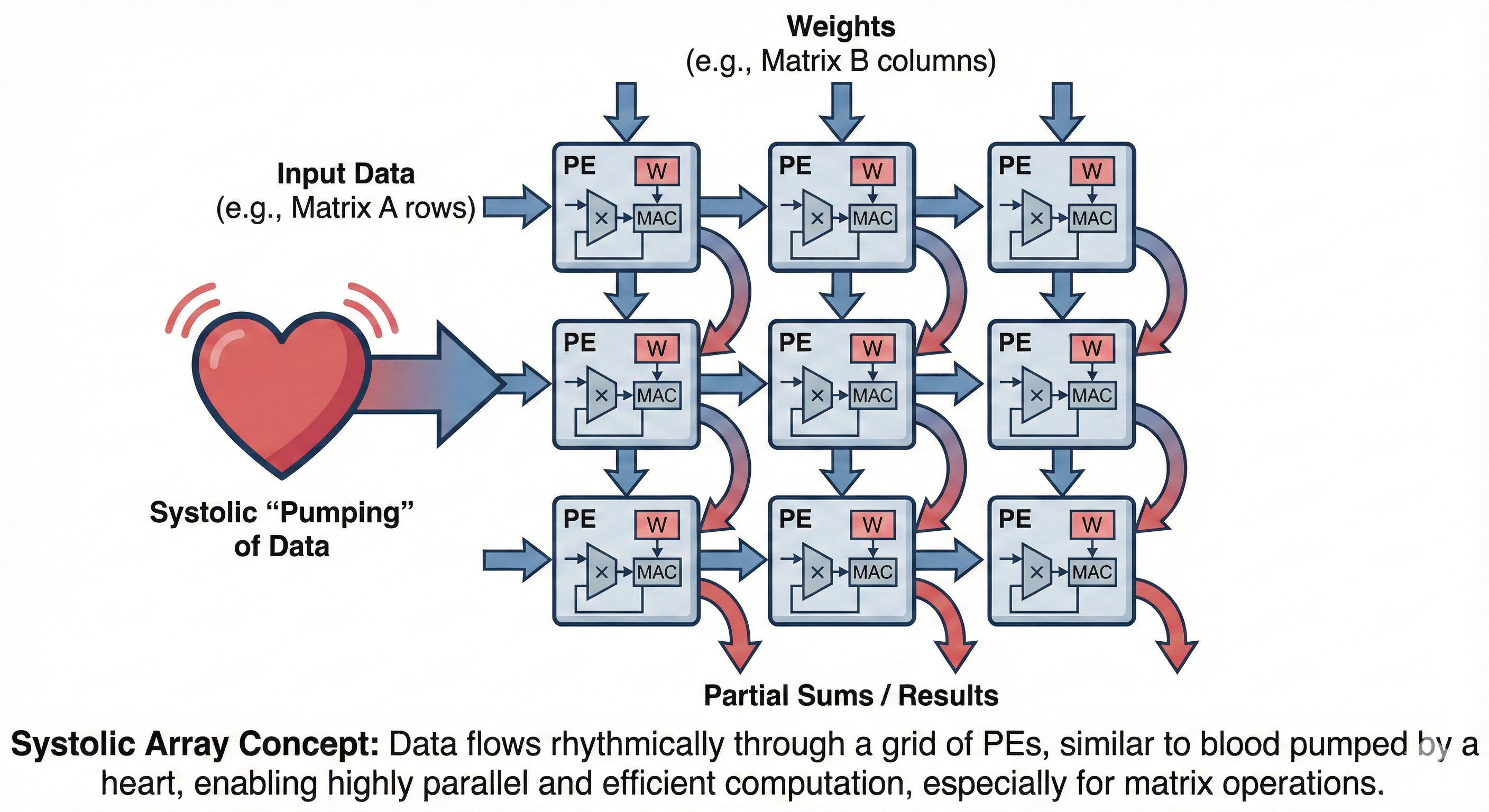
1. Google TPU:資料流優先的 Systolic Array
TPU 並非僅僅是一個「更強的 GPU」,它代表了一種完全不同的哲學:先設計資料流,再設計硬體。 它採用 Systolic Array(脈動陣列) 架構,就像規律的心跳:
每個單元只負責最簡單的「乘法 + 累加」。
資料像血液一樣有節奏地流過陣列。
幾乎沒有指令分支預測,非常契合 Transformer 這種固定型的矩陣乘法。
2. NVIDIA:通用平台的王者
NVIDIA 的 Tensor Core 讓 GEMM 運算變成了硬體級公民,但它的王牌在於「通用性」。
CUDA 生態系、cuDNN 與 TensorRT。
龐大的開發者社群。 這構成了深寬的護城河。NVIDIA 的晶片雖然不是針對單一模型最高效的,但它是最通用、最好用、適應性最強的。
3. ASIC 派(Groq、Cerebras、Etched):把特化做到極致
Groq 提出了激進的主張:延遲(Latency)比吞吐(Throughput)更重要。
拒絕外部 HBM,改用片上 SRAM 作為 KV 倉庫。
Pipeline 完全可預期(Deterministic),沒有動態調度。 這讓 Groq 在處理第一個 token 時極快,但也受限於 SRAM 的容量,難以承載超大模型。而像 Etched 這樣的公司則專為 LLM 推理「刻」晶片,效率驚人,但靈活性極低,一旦模型架構改變,晶片可能就此失效。
Groq LPU 設計精髓:以「確定性」打破記憶體高牆
在 AI 硬體競賽中,Nvidia 的 GPU 憑藉強大的平行運算能力和 CUDA 生態系佔據主導地位,但 Groq 的橫空出世代表了一種截然不同的晶片設計哲學。LPU 並非為了圖形渲染或通用運算而生,它是專為 LLM 推理速度而極致優化的產物。
Groq 設計的精髓可以概括為兩個核心概念:「確定性」與「軟體定義硬體」。以下從三個維度深入剖析:
1. 根除硬體調度,擁抱絕對的「確定性」
傳統 GPU 採用「多核心 + 快取(Cache) + 動態調度器」的架構。當數據進入 GPU 時,硬體調度器會動態決定哪個核心處理哪個任務,數據何時進入快取或記憶體。這種機制雖然靈活,但也帶來了不可預測性——如果發生 Cache Miss(快取未命中)或記憶體爭用,延遲就會產生。對於需要逐字生成(Token-by-Token)的 LLM 來說,這種微小的延遲累積起來就是巨大的效能瓶頸。
Groq 的做法是:完全移除硬體中的動態調度器、分支預測器和快取控制器。
在 Groq 的架構中,一切都在編譯階段就決定好了。Groq 的編譯器確切知道每一個指令在每一個時脈週期會在哪個運算單元執行,數據會在什麼時間點流動到哪裡。這種確定性執行(Deterministic Execution)意味著沒有硬體層面的「猜測」或「等待」,從而消除了硬體管理的 overhead。就像交通系統,GPU 像是設有紅綠燈的繁忙路口(需要動態調整),而 Groq 則是時刻表精確到毫秒的高速鐵路,列車永不誤點,也無需煞車。

2. 擊碎記憶體高牆:SRAM vs. HBM
LLM 推理的主要瓶頸通常不是「算力」,而是「記憶體頻寬」。GPU 依賴 HBM,雖然容量大,但數據仍需從外部記憶體搬運到晶片核心,這段物理距離限制了速度。
Groq 選擇了一條激進的路線:全晶片 SRAM(靜態隨機存取記憶體)。
Groq 的晶片沒有使用外部 DRAM 或 HBM,而是將所有記憶體直接整合在晶片內部的 SRAM 中。SRAM 的速度比 HBM 快得多,且延遲極低。這使得 Groq 的頻寬利用率極高。雖然單顆晶片的 SRAM 容量非常有限(僅約 230MB),無法裝下一個巨大的 Llama-3 模型,但 Groq 透過極高速的晶片間互連解決了這個問題。
Groq 將數百顆晶片串聯,邏輯上視為「一顆巨大的晶片」。因為它是確定性的,編譯器可以將模型權重完美地切分並分佈在數百顆晶片的 SRAM 中,數據在晶片間流動如同在晶片內部一樣順暢。這讓 Groq 在處理 Batch Size = 1 的即時推理時,能展現出驚人的 Tokens per second。

3. TSP 架構:數據流動的流水線
Groq 的架構被稱為 TSP(Tensor Streaming Processor)。其核心佈局並非傳統的「核心陣列」,而是功能切分的「切片」。晶片上不同的區域分別負責矩陣乘法(MXM)、向量運算(VXM)和記憶體讀寫(MEM)。
數據在晶片上的流動是有方向性的(通常是從東向西),指令流則是從北向南。這種設計讓數據像在工廠流水線上依序經過各個加工站,無需來回搬運。這種時序指令集(Temporal Instruction Set)讓軟體能夠精確控制數據在晶片上的空間和時間位置,最大化了運算單元的利用率。

總結
Groq LPU 的設計精髓在於「簡化硬體,複雜化編譯器」。它拋棄了通用處理器為了適應不確定性而設計的複雜電路(Cache, Scheduler),換取了極致的傳輸效率和運算密度。
雖然這種設計面臨著「記憶體容量成本極高」(SRAM 成本遠高於 HBM)的挑戰,需要堆疊大量晶片才能運行大模型,但它成功解決了 LLM 應用中最痛的點——延遲。對於需要即時語音對話、極速代碼生成的場景,Groq 提供了一種物理層面上更優越的解法。
六、晶片路線的博弈:誰押對未來?
這場博弈的決勝關鍵,在於誰能在算力、記憶體容量與互連頻寬之間找到最佳平衡點。
七、軟體的靈魂:編譯器,其實才是 AI 晶片的控制台
硬體如果沒有編譯器,就只是一塊會發熱的石頭。 無論是 Google 的 XLA、NVIDIA 的 CUDA/TensorRT,還是 PyTorch Glow,編譯器決定了算子如何拆解、指令如何排列、數據要放在哪一級快取(Cache)運行。
誰控制了編譯器,誰就控制了生態。 這解釋了為什麼 NVIDIA 難以被撼動——它的護城河不只是 GPU 本身,而是經過十幾年積累、高度優化的整個軟體堆疊。

在探討 AI 晶片與算力競爭時,我們往往將目光聚焦在硬體的規格——誰的製程更先進、誰的記憶體更大。然而,真正決定這些昂貴硬體能否發揮效能的,其實是一個常被忽略、卻至關重要的角色:AI 編譯器。
傳統觀念中,編譯器(如 C++ Compiler)的角色僅是「翻譯」,負責將人類寫的程式碼轉譯為機器能懂的指令。但在 AI 的世界裡,編譯器的難度與職責發生了質變。它不再只是翻譯官,而是調度千軍萬馬的「作戰司令部」。
1️⃣戰略調度:決定算力的真實極限
AI 編譯器處理的對象並非單純的程式碼行,而是整張神經網路計算圖。它的核心任務是對這張圖進行分解、重排、並行化與壓縮,並將其精準地分發到硬體的各個單元。
如果把 AI 模型比作一場大型戰役,編譯器就是在做微觀戰術指揮:
兵種配置:這層卷積運算(Convolution)適合派往 Tensor Core 執行。
糧草補給:這段 KV Cache 必須優先放入 HBM,以確保數據不卡彈。
陣型拆解:這段矩陣乘法太過龐大,需拆解成 128 個區塊(Tile)並行處理。
輕量化作戰:這裡是否能啟用 FP4 量化來換取速度,同時確保精準度不下降?
這意味著,編譯器決定了「怎麼跑」。同樣的模型、同樣的硬體,若換上一套更成熟的編譯器,效能可能直接提升 30% 至 200%。這並非理論,而是近十年來 GPU 訓練與推論優化的鐵律。

2️⃣最後一哩路:將「理論」轉化為「產品」
AI 領域的創新速度極快,Transformer、Mixture-of-Experts(MoE)、FlashAttention 等概念層出不窮。但若沒有編譯器的支持,這些創新只能停留在論文階段。
以 FlashAttention 為例,其本質是優化注意力機制在記憶體上的存取路徑(讓數據「走得更短」)。然而,要讓這個數學上的優化變成開發者人人可用的工具,必須依靠 NVIDIA TensorRT、PyTorch 2.0(Dynamo/Inductor)或 OpenAI Triton 等編譯層的實作。
編譯器是連接「學術論文」與「商業產品」之間的最後一哩路橋樑。許多新創晶片公司之所以失敗,往往不是因為硬體設計不夠酷炫,而是缺乏強大的編譯器堆疊,導致開發者無法將先進的理論模型落地到其硬體上。
3️⃣三大核心戰場:記憶體、並行與量化
AI 編譯器的技術價值,具體體現在它解決了當前 AI 算力的三個核心瓶頸:
Memory Wall:今日 AI 的效能瓶頸往往不在計算速度,而在於「資料搬運」。編譯器必須精算每一筆資料的流向:哪些放 L1/L2 Cache?哪些放 HBM?KV Cache 如何復用?很多看似魔法般的提速,本質上是編譯器在記憶體排程上的勝利。
複雜的並行調度(Parallelism):當模型大到單晶片無法容納,必須依賴 Tensor Parallel 或 Pipeline Parallel 時,如何讓成千上萬顆晶片同時工作而不互相等待(Bubble),靠人力手寫已不可能。這必須仰賴編譯器與 Runtime 的自動調度。
量化與算子融合:從 FP16 到 FP4,每一步壓縮都需要數學驗證與編譯重排。若編譯器不夠智慧,模型雖然跑得快,答案卻會變「笨」。真正厲害的架構,是讓編譯器自動找到「速度與精度」的最佳平衡點。

4️⃣生態護城河:誰掌握編譯器,誰就定義規則
NVIDIA 之所以難以撼動,真正的護城河並非僅在於 GPU 晶體本身,而在於 CUDA + TensorRT + Triton 構築的軟體生態。
NVIDIA 幾乎控制了 AI 程式語言的表達方式、算子的排列邏輯以及記憶體的佈局。當一位工程師打下 import torch 時,他其實已不自覺地選擇了 NVIDIA 的世界觀。這就是所謂的軟體鎖定。
競爭對手如 AMD(ROCm)、Google(XLA/TPU)、Intel(OneDNN)以及 Meta/OpenAI 大力推動的 Triton 與 TVM,本質上都是在進行同一場戰爭:試圖打破編譯器的壟斷。因為所有人都明白:先搶下編譯器的話語權,才有可能搶下硬體的市佔率。

import torch 的通行證走入大門時,他們其實已經進入了 NVIDIA 設定的規則世界。城牆之內是高度整合的舒適圈;城牆之外,則是競爭對手(AMD、Intel、Open Source)試圖在荒原上建立新編譯器堆疊的艱辛縮影。這張圖揭示了 AI 戰爭的殘酷真相:誰掌握了編譯器,誰就擁有了讓開發者「定居」的權力。投資與產業啟示
縱觀半導體歷史,硬體往往負責初期的「吸睛」,但最終的「獲利」與「控制權」總是落在軟體與標準制定者手中。
短期看硬體:誰的晶片快、誰的 HBM 大。
長期看編譯器:誰能讓開發者最順暢地部署模型。
對於 AI 晶片新創而言,沒有編譯器,就永遠只能做別人的外包,無法進入主流框架;而對於巨頭而言,掌握編譯器就掌握了生態的議價權。這也是為什麼 NVIDIA 不急著降價,Google 堅持自研 TPU,而 OpenAI 即使不賣晶片也要投資自家編譯器工具的原因。
八、物理極限登場:記憶體牆與 KV Cache
隨著人工智慧模型規模突破百億、千億甚至兆級參數,產業焦點正在發生根本性的轉移。如果說 AI 的訓練階段是典型的「算力受限(Compute-Bound)」場景,那麼 AI 推理正一步步跌入「記憶體受限(Memory-Bound)」的深淵。
當前的核心瓶頸已不再是 GPU 的計算核心跑得不夠快,而是資料無法「夠快、夠便宜」地搬運到算力單元旁邊。這就是經典的 Memory Wall 問題:處理器的計算速度呈指數級增長,但記憶體的頻寬與延遲改善卻相對緩慢,導致處理器在大部分時間裡並非在運算,而是在「等待資料」。

1️⃣硬體解法:HBM 與先進封裝的生命線
為了突破記憶體牆,HBM 成為了現代 AI 的生命線。HBM 之所以爆紅,是因為它從物理層面解決了兩大關鍵痛點:
極致的頻寬: 傳統 DDR 或 GDDR 的頻寬遠遠不足以餵飽現代 GPU 的矩陣運算引擎。HBM 透過極寬的匯流排設計,提供了維持算力飽和所需的吞吐量。
縮短物理距離: HBM 不再通過長長的主機板線路連接,而是透過先進封裝(如台積電 CoWoS、Intel EMIB)直接「堆疊」在 GPU 旁。這不僅大幅降低了延遲,也顯著減少了資料搬運的功耗。
因此,先進封裝已不再是附加價值,而是「把記憶體變快」的唯一物理途徑。 沒有 CoWoS,就沒有 NVIDIA H100/GB200;沒有 HBM,就沒有今天的大型語言模型(LLM)推理能力。
然而,這也帶來了殘酷的代價:HBM 成本高昂、良率受制於「短板效應」(多晶片堆疊中一顆損壞即整顆報廢),且供應鏈高度集中(SK 海力士、三星、美光)。這導致半導體產業的利潤池正在重分配——價值從單純的「邏輯算力」向「記憶體與封裝」轉移。

2️⃣架構歧路:ASIC 的極致與侷限
面對記憶體牆,Groq、Cerebras、Etched AI 等 ASIC 新創公司選擇了另一條激進的道路:既然搬運資料昂貴,那就把記憶體直接搬進晶片裡。
這些架構採用大量片上 SRAM,其優勢在於極低的延遲和與算力同頻的頻寬,在處理特定推理模式時效率驚人。然而,這種設計面臨著致命的物理限制:
成本與面積: SRAM 的面積巨大且成本極高。
良率與價格: 晶片越大,良率越差,價格呈指數上升。
容量瓶頸: SRAM 的容量始終無法與 HBM/DRAM 相比。
因此,SRAM-based ASIC 本質上是在犧牲泛用性與容量,以換取極致的低延遲。當模型參數持續膨脹、「上下文(Context)」不斷變長時,「塞不下」將成為這類架構難以跨越的結構性障礙。

優勢: 這種設計消滅了資料傳輸的距離,讓頻寬與算力同步,實現了極致的低延遲。
代價: 為了換取速度,犧牲了泛用性與容量。一旦模型參數過大或上下文過長,這顆昂貴的晶片就會面臨「塞不下」的物理極限。
3️⃣核心瓶頸:KV Cache 的成本黑洞
在 Transformer 架構的推理過程中,隱藏著一個巨大的資源黑洞——KV Cache(鍵值緩存)。
為了提高效率,模型在生成新 Token 時,不會重新計算過去的序列,而是將過去的 Key/Value 儲存起來。這看似聰明,卻帶來了三個致命後果:
記憶體佔用的線性爆炸: KV Cache 的大小隨著「輸入長度 × 層數」線性增長。當上下文越長,Cache 就像滾雪球般佔據大量顯存(VRAM),導致伺服器必須保留記憶體來「存資料」而非「做運算」。
推理變成「頻寬遊戲」: 每生成一個 Token,GPU 都必須從龐大的 KV Cache 中拉取資料進行注意力運算。此時瓶頸完全卡在記憶體頻寬上,算力利用率低,但電費與硬體折舊卻在持續燃燒。
併發能力封頂: 企業最終發現,限制服務用戶數(Concurrency)的不是算力,而是 KV Cache 佔滿了記憶體。80% 的推理成本,其實源於記憶體佔用與頻寬消耗。

4️⃣技術突圍:正面挑戰記憶體效率
為了解決 KV Cache 帶來的成本問題,新一代的軟硬體架構正在發起一場效率革命。無論是 Meta 的 Context Parallelism、NVIDIA 的 FP4 量化、DeepSeek 的 MLA(Multi-Head Latent Attention)架構,還是 PagedAttention 等新算法,矛頭都指向同一個戰場:
「如何少存一點 KV?如何更快地搬運?如何用更少的記憶體完成同樣的推理?」
這不僅僅是工程優化,更是決定 AI 推理成本曲線能否下降的關鍵。
市場啟示:價值鏈的重組
在「記憶體牆」的制約下,未來 3-5 年硬體價值鏈將由以下三類玩家主導:
HBM 與先進封裝(必然受益者): 記憶體成為新黃金,而封裝是開啟金庫的鑰匙。SK 海力士、三星、美光以及掌握 CoWoS/SoIC 技術的台積電是最大贏家。
能降低 KV Cache 成本的效率革命者: 能夠從演算法(如 FlashAttention)、編譯器(Runtime/Compiler)或專用晶片(ASIC)層面降低每 Token「記憶體成本」的公司,將改寫商業模型。
壓縮記憶體需求的軟體槓桿: 透過量化(FP8/FP4)、蒸餾、稀疏化(Sparsity)以及高效 Serving 系統(如 vLLM)來降低需求的軟體技術。軟體每節省 10% 的記憶體,就等於為企業節省了巨額的 GPU 採購成本。
九、資料互連:算力工廠的「血管系統」
隨著模型參數突破兆級,單顆晶片已無法獨力完成任務,算力變成了一個分散式系統問題。這使得 Broadcom 和 Marvell 等公司變得至關重要,因為他們控制著 GPU 與 TPU 之間的「交通」。
目前的兩大技術路線:
Packet Switching(封包交換): 使用乙太網與交換器。優點是通用、靈活;缺點是有排隊延遲與抖動(Jitter)。
OCS(光路交換): 直接在兩台機器間拉一條光路。優點是延遲極低且穩定,適合大批量、規律的訓練流量;缺點是配置複雜且成本高昂。
未來的趨勢將是「封包 + 光路」並存,依據工作負載(Workload)自動切換,構建更高效的算力叢集。
這是一份經過梳理、潤飾後的完整論述。我將原本的零散觀點組織成一篇邏輯嚴密、層次分明的產業分析文章,適合用於內部報告或深度產業研究。
1️⃣典範轉移:從「單兵作戰」到「分散式合唱」
隨著 AI 模型參數正式突破兆級(Trillion Parameters),單顆晶片的物理極限已無法獨力承擔運算任務。算力的本質,已經從單純的「晶片效能問題」轉變為複雜的「分散式系統問題」。
在這個新時代,GPU 不再是戰場上的孤膽英雄,而更像是一支龐大的合唱團,必須透過毫秒不差的同步合作才能完成演出。於是,一個新的權力中心隨之誕生——誰控制了「資料交通」,誰就掌握了 AI 工廠的運作效率。這正是為何 Broadcom、Marvell、NVIDIA(憑藉 NVLink / NVSwitch)以及新創光通訊公司在當前市場中變得舉足輕重的核心原因:它們掌握了「GPU 與 TPU 如何對話」的關鍵能力。

2️⃣ 瓶頸所在:昂貴的 GPU 為何在「空轉」?
為什麼「互連技術」(Interconnect)如此關鍵?在大型語言模型(LLM)的訓練與推論過程中,系統必須處理三種極高負載的流量:
參數同步(Parameter Synchronization): 如 All-Reduce 和梯度同步。
激活值傳遞(Activation Transfer): 在前向與後向傳播間的資料流動。
分散式存取(Distributed Access): 涉及 KV Cache 與查詢資料的調度。
若互連頻寬不足或延遲(Latency)過高,將導致一個災難性的後果:昂貴的 GPU 大部分時間都在「等待資料」。這解釋了為何當前許多 AI 算力叢集的實際利用率(MFU)僅徘徊在 50–60% 左右。制約效能的瓶頸根本不在於「心臟」(GPU),而在於擁塞的「血管」(互連網路)。
3️⃣技術路線之爭:封包交換 vs. 光路交換
為了解決上述瓶頸,目前產業主要存在兩條技術演進路線:
1. 封包交換(Packet Switching)—— 通用與彈性的代表
技術基礎: 以太網(Ethernet)加上交換器(Switch),代表技術包括 RoCEv2 與 InfiniBand。
優勢: 具備高度通用性與彈性,產業生態成熟,易於擴充至數萬顆 GPU 規模。軟體與韌體層面有持續優化空間(如流量控制、壅塞管理)。
劣勢: 天生存在排隊延遲與抖動(Jitter),在高負載下容易壅塞,影響傳輸的可預測性。
NVIDIA 的策略: 花費十多年打磨 InfiniBand,本質上就是為了將「通用網路」的效能逼近「專用互連」的極致。
2. 光路交換(OCS, Optical Circuit Switching)—— 極致效率的專線
技術概念: 不再將資料切分成封包,而是透過光學鏡面反射,直接在兩台機器間建立物理上的「專線」。
優勢: 幾乎零排隊延遲,無抖動(Jitter-free),傳輸極其穩定。特別適合大批量、規律性的訓練任務及全叢集同步(All-Reduce)。
劣勢: 路由需預先規劃,配置困難,動態彈性差,且硬體維護成本高昂。
Google 的策略: 近年強力推動 OCS,目的即是在超大規模訓練中,將「叢集延遲」降至物理極限。

4️⃣未來架構:混合型「智慧調度」
真正的答案並非在兩者間「二選一」,未來的 AI 網路架構將走向 「封包 + 光路」共存 的混合模式。這就像現代城市的交通系統:我們同時需要 高速公路(OCS) 來處理固定、大流量的長途運輸,也需要 城市道路(Ethernet) 來應對靈活、多變的短程需求。
未來的系統將依據工作負載自動分流:
訓練階段(規律大流量): 走 OCS 通道,確保最高效率。
推論階段(多租戶、小批次): 走封包交換,確保靈活性。
混合負載: 進行動態即時切換。
因此,真正的技術挑戰與下一個戰場,在於「如何做智慧調度」——即如何讓每一位元的資料流量,自動選擇最合適的路徑。

產業護城河的演變與投資啟示
AI 產業的競爭護城河正在經歷三階段的演化:
昨天: 護城河在 GPU 算力。
今天: 護城河在 互連頻寬與網路堆疊。
明天: 護城河在 「誰能最聰明地管理流量與 KV Cache」。
給投資人與研究員的關鍵啟示:
重新定義 Broadcom / Marvell: 它們不應再被視為單純的「硬體附屬商」,它們正在晉升為 AI 工廠的「交通部長」,掌握著基礎設施的命脈。
NVIDIA 的真正壁壘: 其優勢絕不僅限於 GPU 晶片本身,NVLink + NVSwitch + InfiniBand 所構成的封閉生態系,創造了極高的替代門檻。
OCS 的長期滲透: 光學交換不會在一夕間爆發,而是採取「由上而下」的滲透路徑——先佔領超大型訓練叢集,再隨著技術成熟慢慢下沉。
標準制定權的爭奪: 未來誰能將「封包交換 + OCS 光路 + KV Cache 管理」整合得最好,誰就能制定下一代 AI 叢集的架構標準,成為真正的產業霸主。
總結:把所有拼起來
—— 演算法改變了架構,架構改變了市場,市場逼近物理極限
回顧這段演化史,Self-Attention 並不只是一個單純的技術突破,它引發了一場「工業革命級」的連鎖反應:
演算法變了: 從 RNN 的序列依賴,轉變為 Transformer 的全面並行。
計算圖扁平化: 從時間鍊條變成了空間矩陣。
晶片架構重寫: Matrix Engine、Systolic Array 與 ASIC 應運而生。
編譯器成為靈魂: 軟體對資料流與排程的控制力決定了硬體效率。
記憶體成為王: HBM、SRAM 與 KV Cache 的管理成為勝負手。
互連成為瓶頸: 交換器、光通訊與叢集拓樸開始主導整體性能。
最後,當我們在分析 NVIDIA、AMD、Google 或 Broadcom 時,我們看似在分析股票或公司策略,其實我們是在追蹤一條數學公式(Attention)如何一步步逼近物理世界的邊界。
而在這條路上,每一層——從最抽象的演算法到最硬核的封裝互連——都在同時進行著激烈的重新洗牌。這就是算力演化的全貌。
Attention 機制的核心思想在於讓模型學會「劃重點」:在處理信息時,模型會主動為不同單詞分配權重,知道哪些信息重要需多加關注,哪些可以忽略。
其具體運作依賴於三種身份矩陣:查詢(Query, Q)、鍵(Key, K)值(Value, V)。
• Q 代表單詞正在「尋找」什麼信息。
• K 代表單詞具備什麼「身份」供他人查詢。
• V 則是匹配成功後要傳遞的「具體含義」。
計算過程中,模型透過 Q 與 K 的點積運算來衡量單詞間的相關性,經由 Softmax 函數轉化為權重(機率分佈),最後將權重與 V 相乘,使原始向量吸收上下文信息並產生偏移,進化為更精確的語義表示。
此外,多頭注意力(Multi-head Attention) 機制允許模型並行運行多個分支,從語法、代詞關係或情感等多個視角同時觀察數據。這種設計不僅解決了長距離依賴難題,更因其極其適合 GPU 並行運算,成為今日 GPT、Claude 等大語言模型的共同核心架構。
以下將模型分成五個步驟來說明:
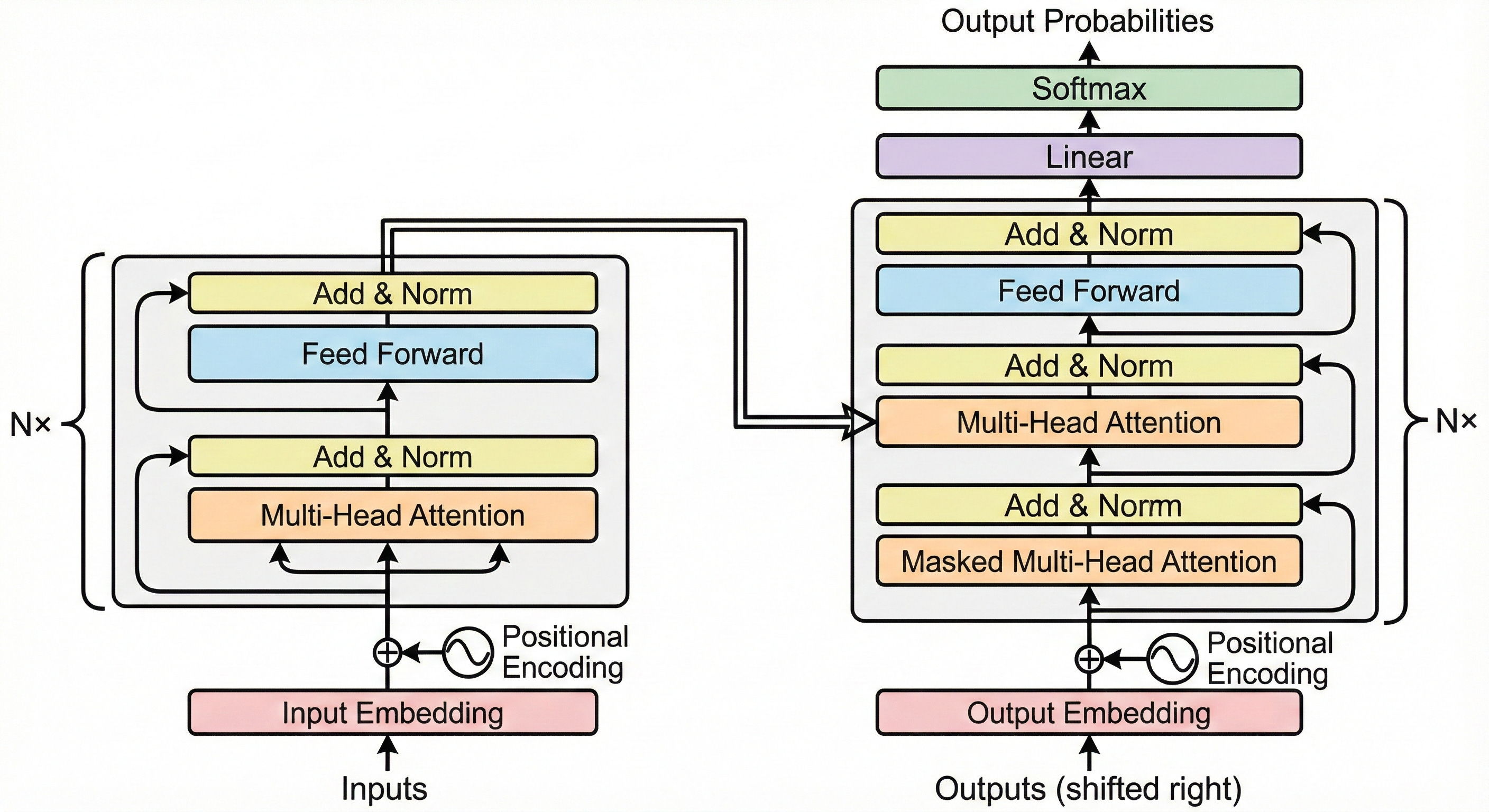
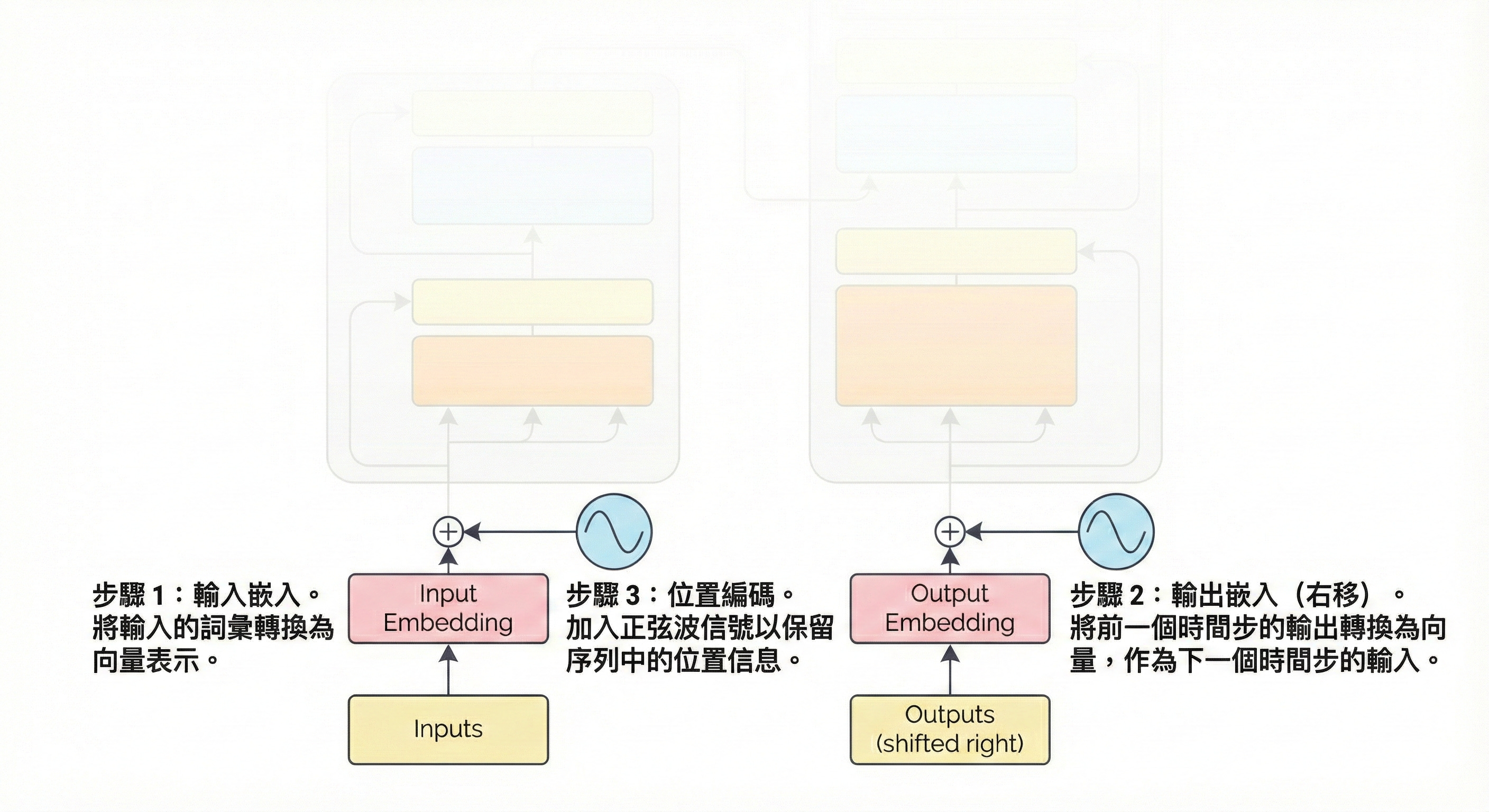
步驟 1:數位化與定位 (Data Preparation)
將語言轉化為數學座標
這是 Transformer 的起點。電腦無法直接理解文字,因此我們首先透過 Input Embedding 將每個單詞轉換為一串數字向量(就像給每個詞一個專屬的身份證號碼)。
然而,Transformer 是並行處理所有文字的,它天生不知道「我愛你」和「你愛我」的區別。為了補足這一點,我們引入了 Positional Encoding(位置編碼),它像是一個時間戳記,加到向量中,讓模型能分辨單詞的先後順序。
核心功能: 詞向量化、賦予順序感。
圖解重點: 關注底部的粉紅色區塊與波浪圖示。
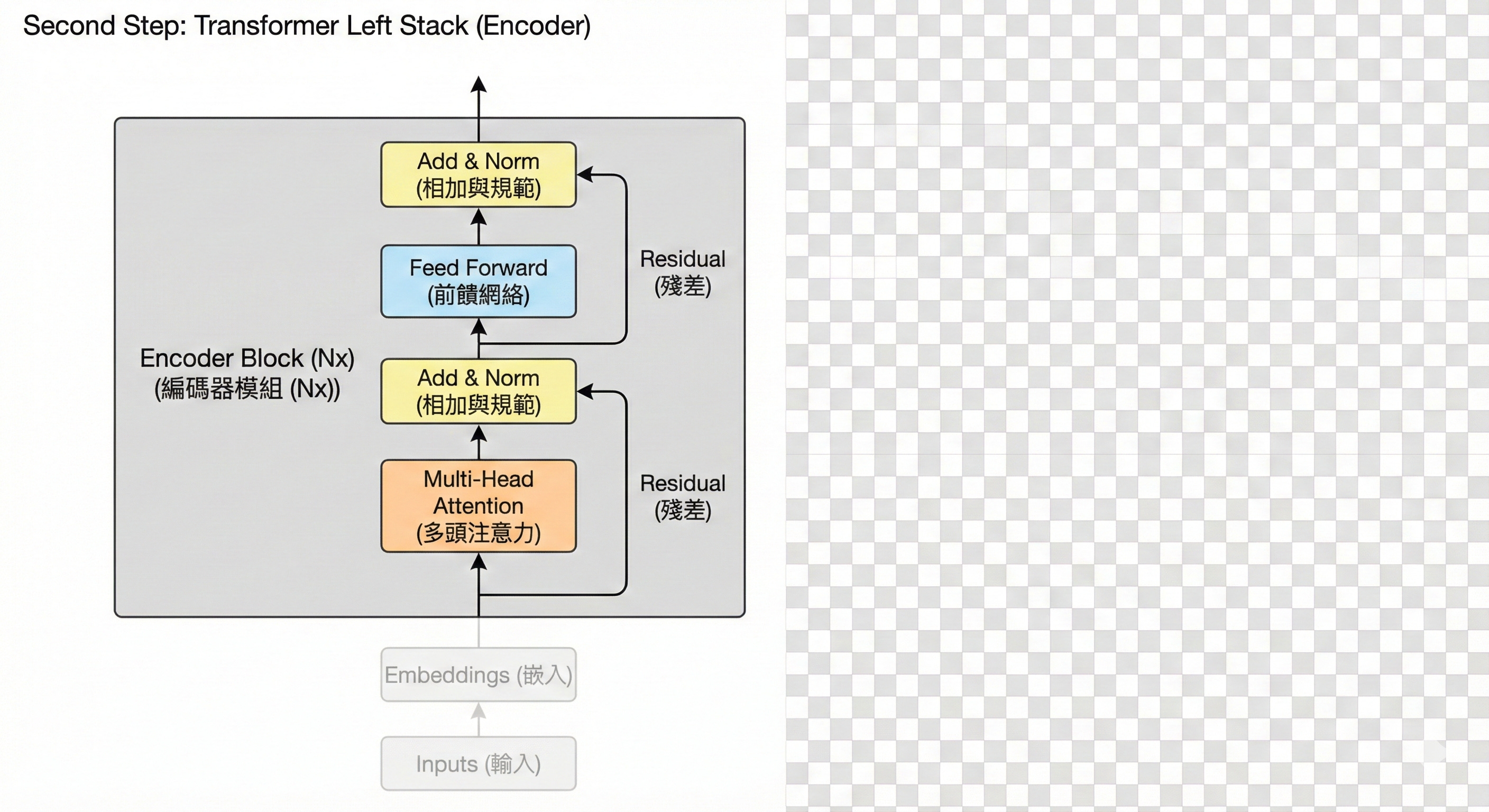
步驟 2:編碼器——全盤理解 (The Encoder)
標題:深度解析上下文的「自注意力」
編碼器(左側堆疊)負責「閱讀並理解」輸入的句子。這裡的核心是 Multi-Head Self-Attention(多頭自注意力機制)。
當模型讀到一個詞時,它會同時查看句子中其他所有的詞,計算它們之間的關聯性。例如讀到「蘋果」時,如果上下文有「吃」,它會知道這是水果;如果有「手機」,它會知道這是科技產品。經過 N 層這樣的處理,模型就提取出了豐富的語義特徵,形成了一組包含完整上下文資訊的「記憶庫」。
核心功能: 捕捉長距離依賴關係,理解詞與詞之間的語義關聯。
圖解重點: 左側灰框內的運作流程。
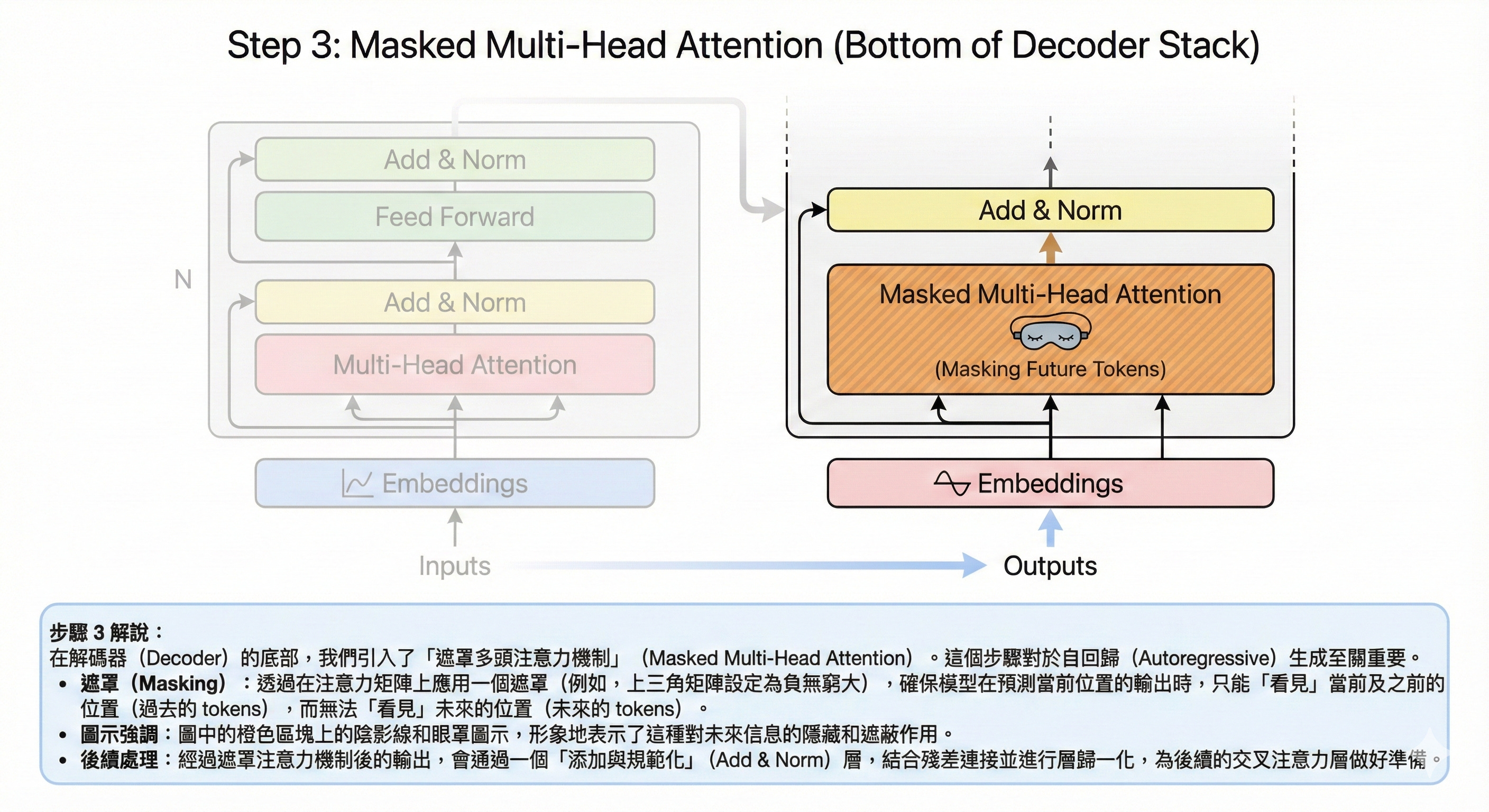
步驟 3:解碼器——受控生成 (Decoder - Masked Attention)
不偷看答案的預測練習
解碼器(右側堆疊)開始工作。它的任務是根據目前的狀態,生成下一個詞。但在訓練過程中,為了防止模型「作弊」偷看到後面還沒生成的正確答案,我們使用了 Masked(遮罩) 機制。
這個機制強迫模型在預測第 3 個字時,只能看第 1 和第 2 個字,將第 3 個字之後的資訊全部蓋住。這確保了模型學會的是「推理」,而不是「背誦」。
核心功能: 基於已生成的歷史資訊進行推理,嚴格遵守時間因果。
圖解重點: 右側下半部,強調「遮罩」的概念。
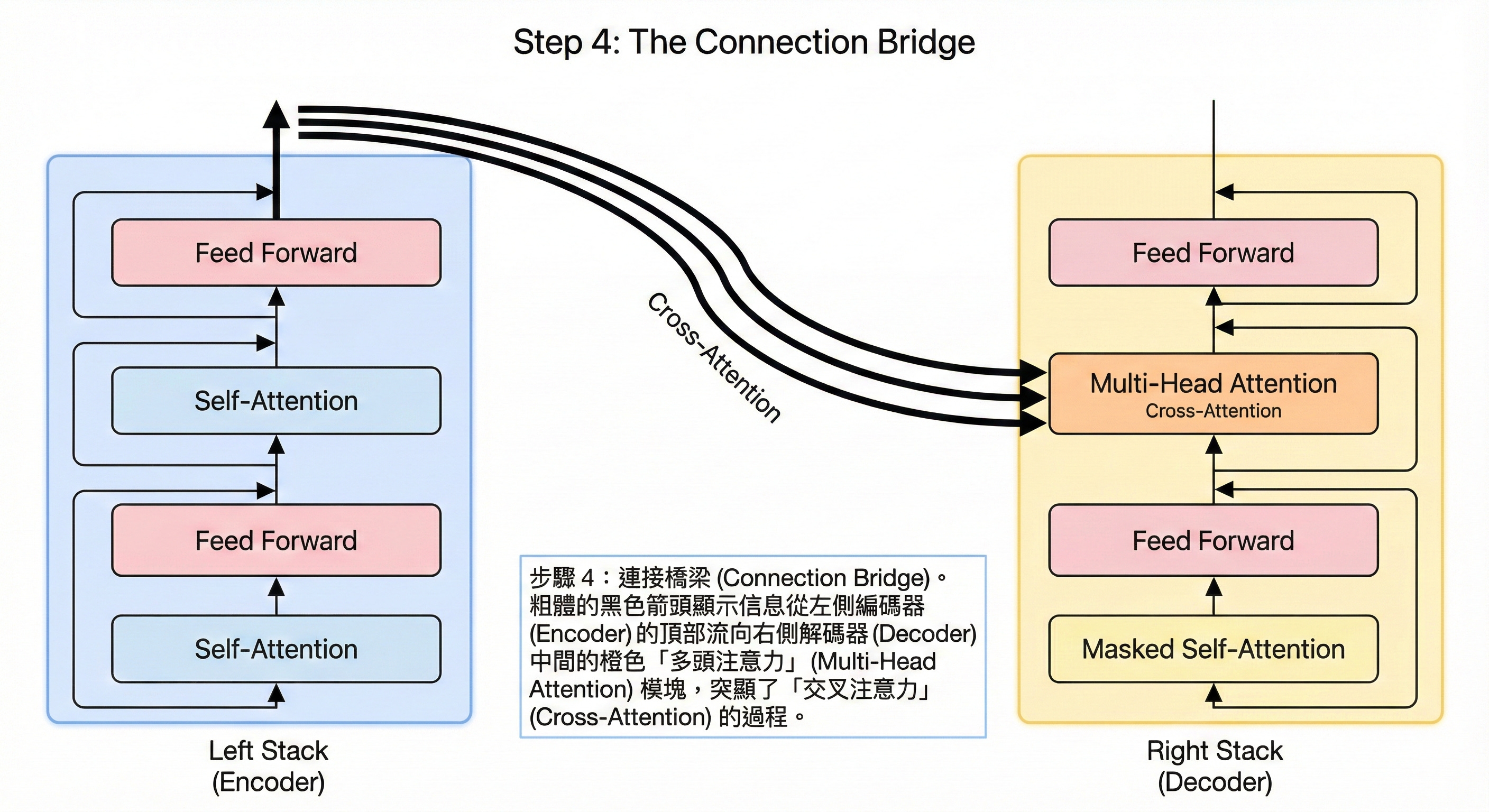
步驟 4:橋樑——交叉注意力 (Cross-Attention)
翻譯發生的時刻——連結原文與譯文
這是整個架構最精妙的地方(右側中間部分)。解碼器利用 Cross-Attention(交叉注意力) 機制,將「編碼器的記憶庫(原文資訊)」與「解碼器目前的進度」結合起來。
想像一個翻譯官,他已經翻譯了一半的句子(解碼器狀態),現在要翻譯下一個詞。他會回頭去查閱原文(編碼器輸出),聚焦在與當前語境最相關的那幾個原始單詞上。這一步驟讓輸出的內容緊扣原文含義。
核心功能: 將源語言的語義映射到目標語言的生成過程中。
圖解重點: 從左側編碼器連向右側解碼器的關鍵箭頭。
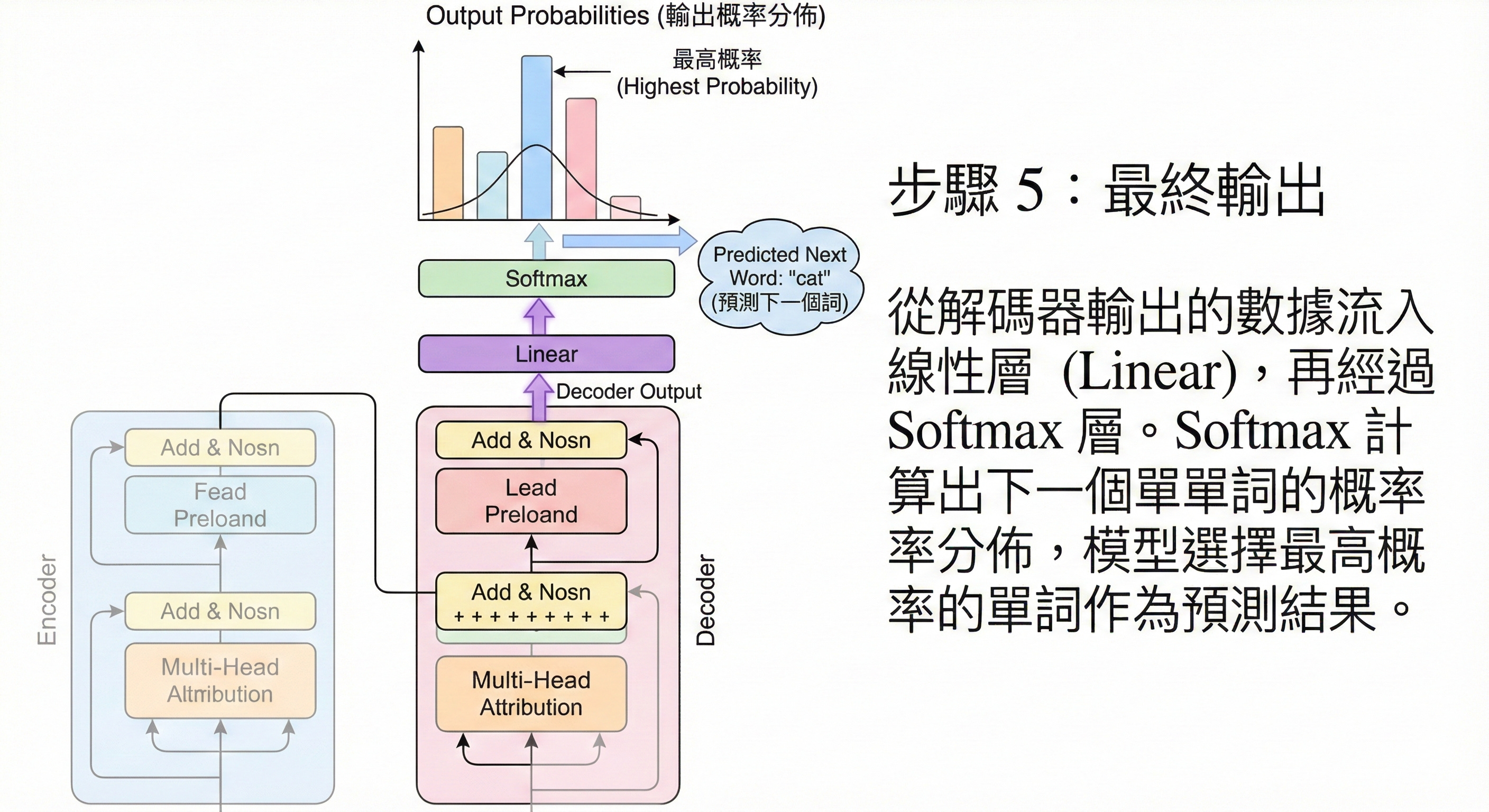
步驟 5:終點——機率輸出 (Final Output)
從向量回歸文字
經過層層處理,解碼器輸出了一組抽象的向量。最後一步,我們通過 Linear(線性層) 將這個向量映射到詞彙表的大小(例如 5 萬個維度),接著通過 Softmax 層將數值轉化為機率分佈。
系統會找出機率最高的那個詞(例如有 90% 的機率是 “Cat”),將其作為最終輸出的單詞。接著,這個新生成的單詞會被放回輸入端,開始下一輪的循環,直到生成結束符號為止。
核心功能: 計算下一個詞出現的機率,完成生成。
圖解重點: 頂部的 Linear 層與 Softmax 機率長條圖。
這篇就倆字牛B
這篇太優了